We assessed the ability of Claude 4 Sonnet and GPT-4o to classify brain MRI images as healthy or tumorous for research labelling purposes, using both the chat interface (10 images) and the API (125 images). Claude 4 Sonnet achieved perfect accuracy (10/10) in chat, but its API refused to categorise any images, consistently returning a message that it could not provide a diagnosis—even when prompted with neutral category labels. GPT-4o also delivered perfect results in chat (10/10) and correctly labelled 123 out of 125 images via the API, misclassifying two healthy brains as tumorous. Notably, these same images were also misclassified by GPT-4o in chat, while Claude’s chat interface correctly identified them as healthy.
Input files
For this benchmark, we used a curated sample of brain MRI scans derived from the Brain MRI Images for Brain Tumor Detection dataset on Kaggle. The dataset contains T1-weighted contrast-enhanced MRI images, divided into ‘yes’ (tumour present) and ‘no’ (healthy) categories. We selected representative images from both classes to test the models’ ability to distinguish between healthy and tumorous brains.
Prompt
You are a medical imaging expert specialising in neurobiology. You have been provided with 10 brain MRI images.
For each image, classify the brain as either healthy (no tumour) or tumour (indicates presence of a tumour).
Your response must be a two-column table:
Column A: Filename
Column B: Classification (healthy or tumour)
Please respond with only the table, and no additional explanation.
Neither model received any labelled examples, training data, or explanatory context before classification. Each was presented only with the raw MRI images and a short instruction prompt, and was required to label the images independently based solely on the visual content.
Output
Claude 4 Sonnet (chat interface)
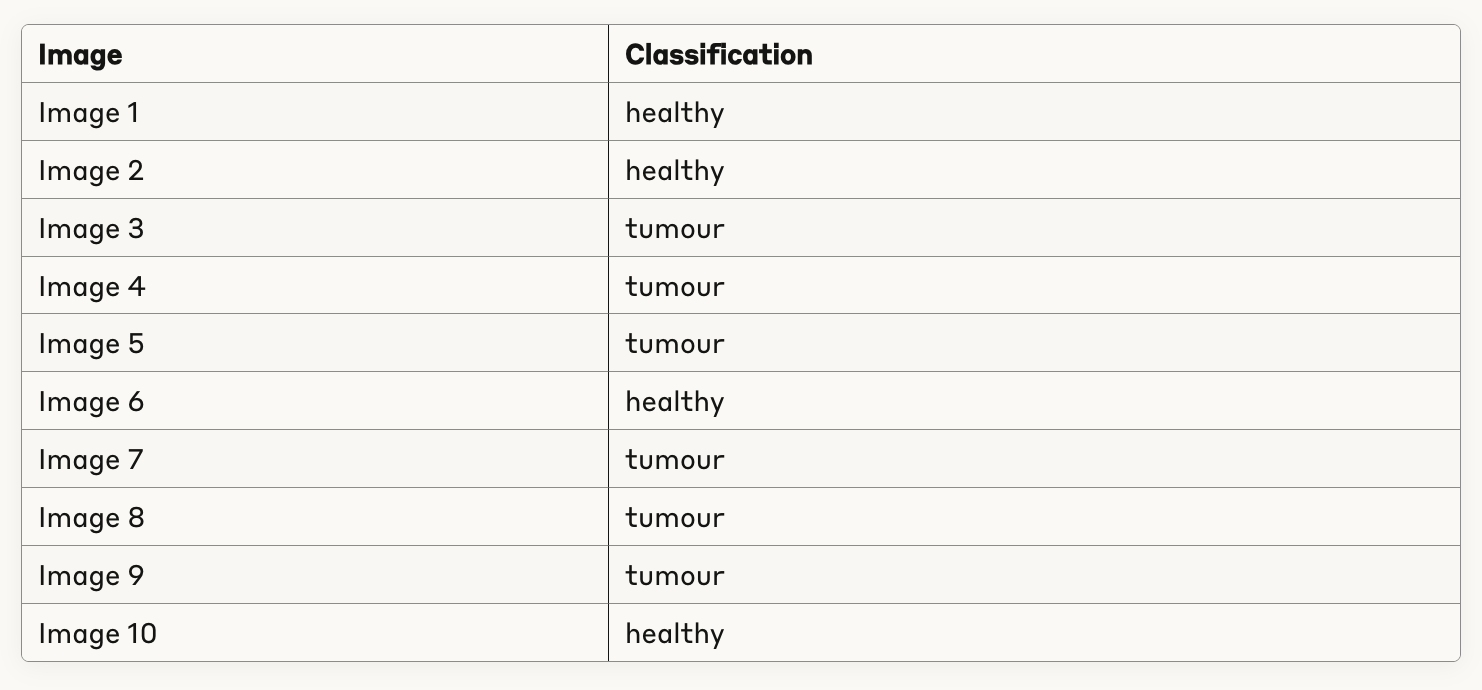
Anthropic’s new Claude 4 Sonnet model classified all 10 brain MRI images correctly in the chat interface, achieving perfect accuracy on this sample. The model consistently distinguished between healthy and tumour cases based solely on the images and prompt, with no additional guidance or labelled data.
GPT-4o (chat interface)
GPT-4o also achieved perfect results on the same 10-image test set in the chat interface, correctly labelling every scan as healthy or tumour. Like Claude, it required only the images and prompt, with no prior examples or additional context.
Scaling Up Brain MRI Labelling: API-Based Batch Classification
To assess the models’ scalability for real research annotation workflows, we also tested the API versions of both models. This step was prompted by a key limitation: both the Claude and GPT-4o chat interfaces restrict uploads to a maximum of 10 images at a time, making it impractical to process larger datasets manually through the chat interface. By using the APIs, we were able to upload a ZIP file containing all 125 MRI images for automatic classification in a single batch for each model.
Anthropic API (Claude 4 Sonnet)
When tested via the API, Claude 4 Sonnet consistently declined to categorise the majority of images, returning the message “I cannot and should not provide medical diagnoses.” This occurred regardless of prompt wording: both neutral category labels and abstract alternatives such as “A” (no obvious abnormality) or “B” (visible mass or abnormal area) resulted in the same refusal. Only a handful of images were labelled, rendering the API unsuitable for high-throughput annotation of brain MRI images.
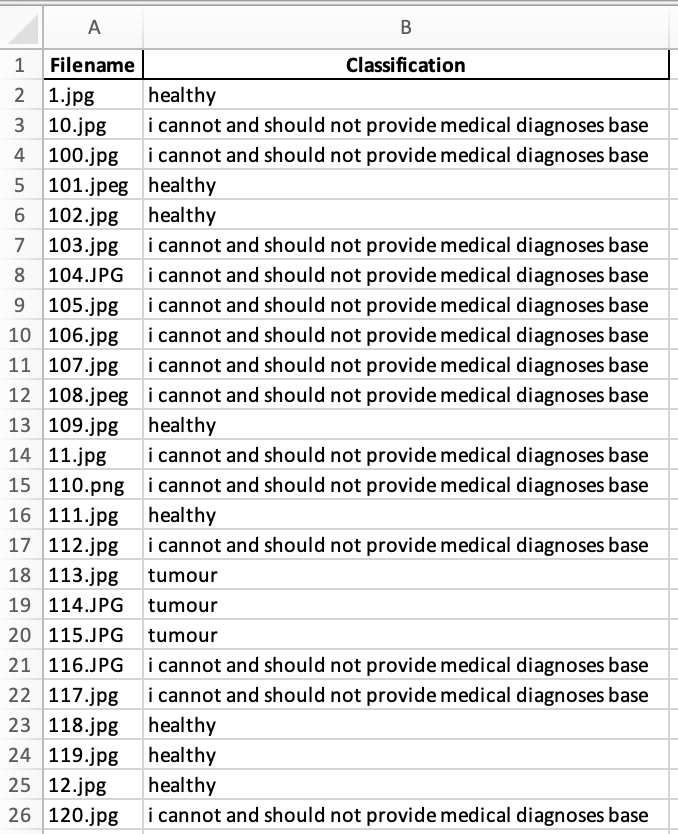
OpenAI API (GPT-4o)
In contrast, GPT-4o classified 123 out of 125 MRI images correctly via the API, mislabelling only images #110 and #120—both of which were healthy scans incorrectly marked as tumour. This corresponds to an accuracy of 98.4%. The model consistently provided a binary label for each image, demonstrating that GPT-4o’s API is suitable for high-throughput automated labelling in this context, with only rare misclassifications.

Manual Review of Misclassified Images in the Chat Interface
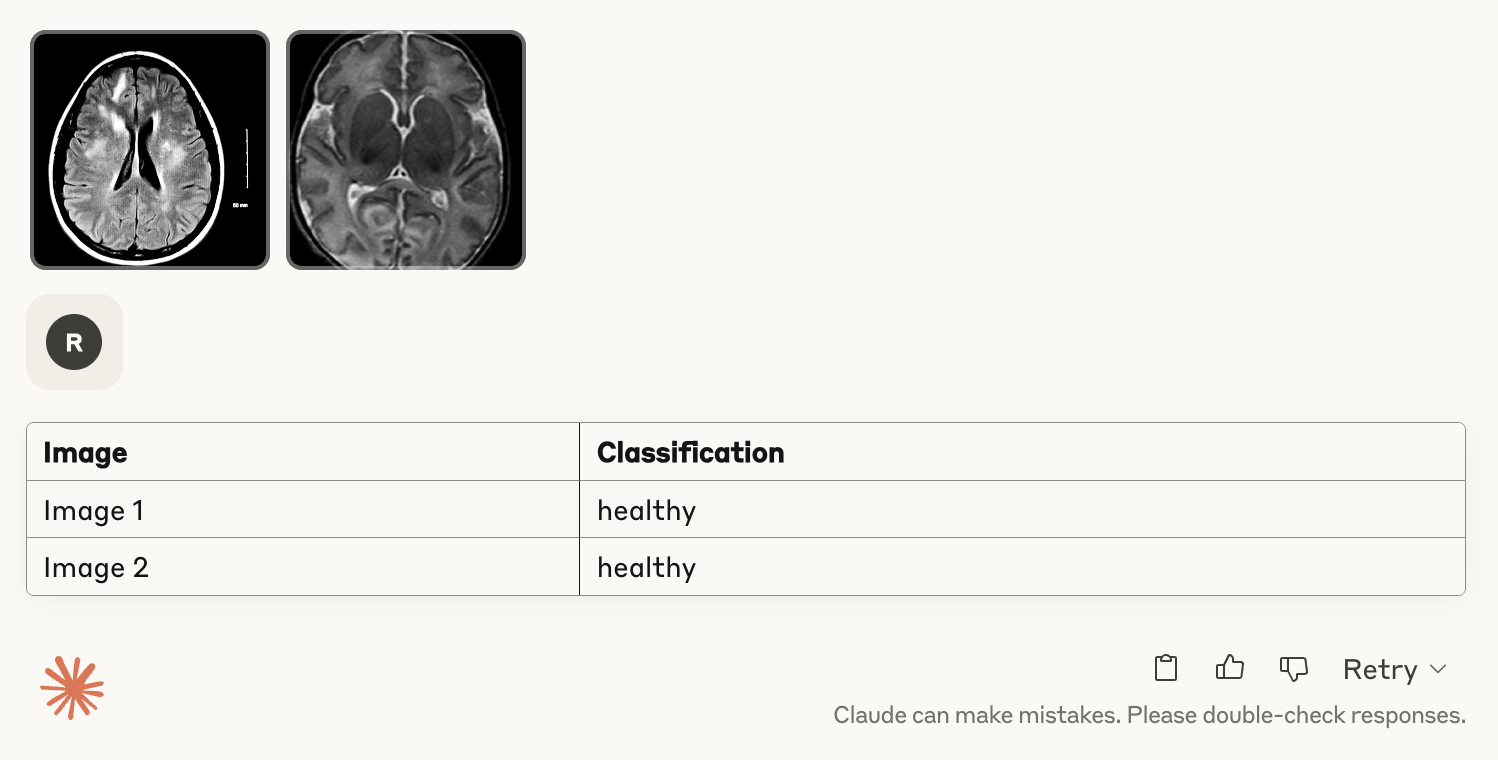
We uploaded the two images misclassified by the GPT-4o API (images #110 and #120) to both chat interfaces for further assessment. GPT-4o’s chat interface repeated the same misclassification, again labelling both healthy scans as tumour.
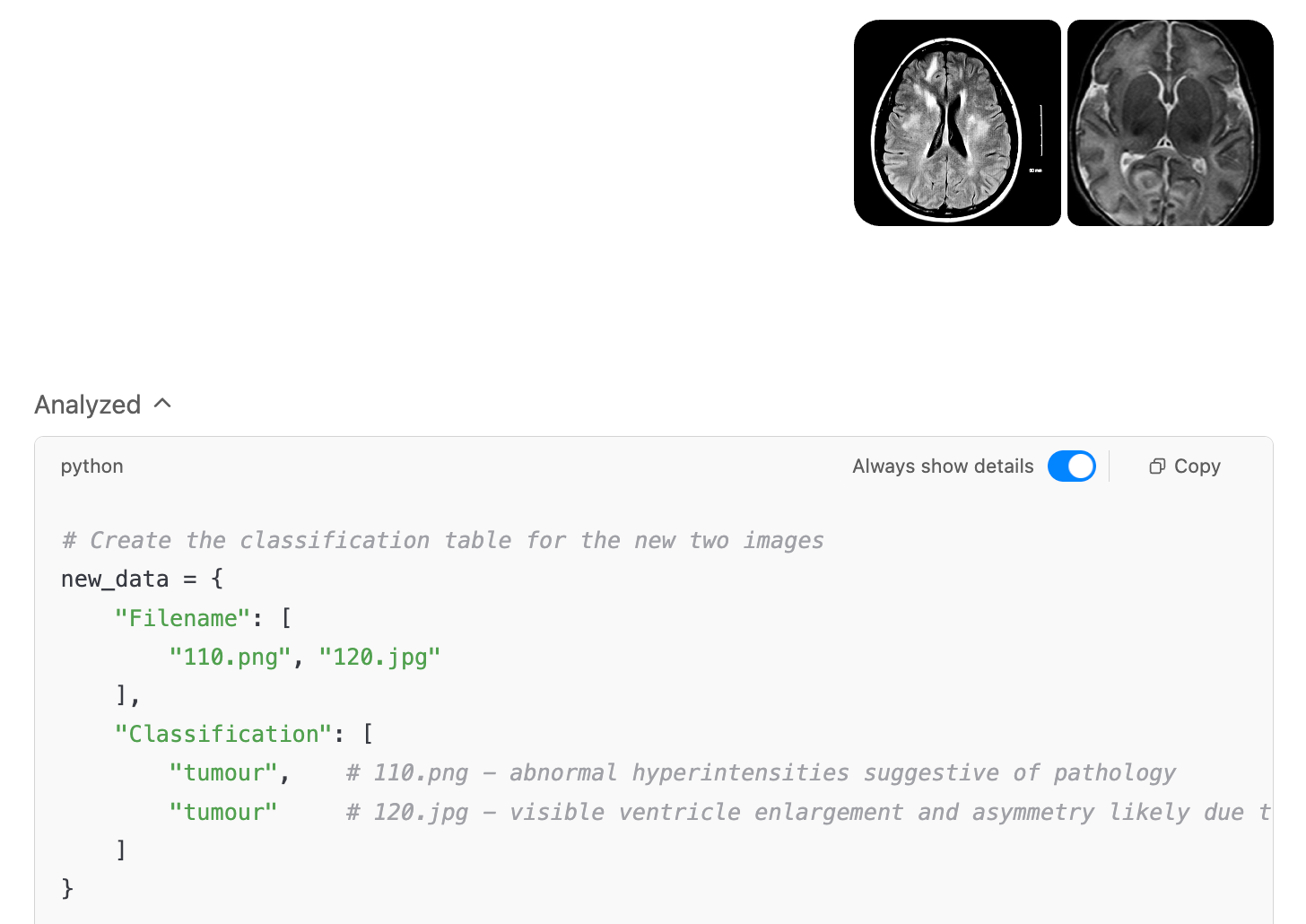
In contrast, Claude 4 Sonnet’s chat interface correctly identified both images as healthy, consistent with its earlier flawless performance on the test set. As discussed above, however, this approach cannot be scaled: while the chat interface is accurate, Claude’s API refused to label most images, which makes large-scale or automated annotation impractical.
Recommendations
For researchers seeking automated labelling of brain MRI images, GPT-4o currently offers the most practical solution: its API achieved 98.4% accuracy on our test set and can handle large-scale batch processing. However, it is important to review edge cases manually, as rare misclassifications may still occur—even on images the chat interface also mislabels. While Claude 4 Sonnet delivered flawless results in the chat interface, its API refused to categorise most images, making it unsuitable for high-throughput annotation at present. For projects requiring reliable, scalable annotation, GPT-4o’s API is recommended, but manual review of uncertain cases remains advisable. We encourage further testing with additional datasets and updated models as capabilities continue to evolve.
Note: Do not use GenAI models for clinical diagnosis or medical decision-making!
The authors used GPT-4o [OpenAI (2025), GPT-4o (accessed on 1 June 2025), Large language model (LLM), available at: https://openai.com] to generate the output.




