
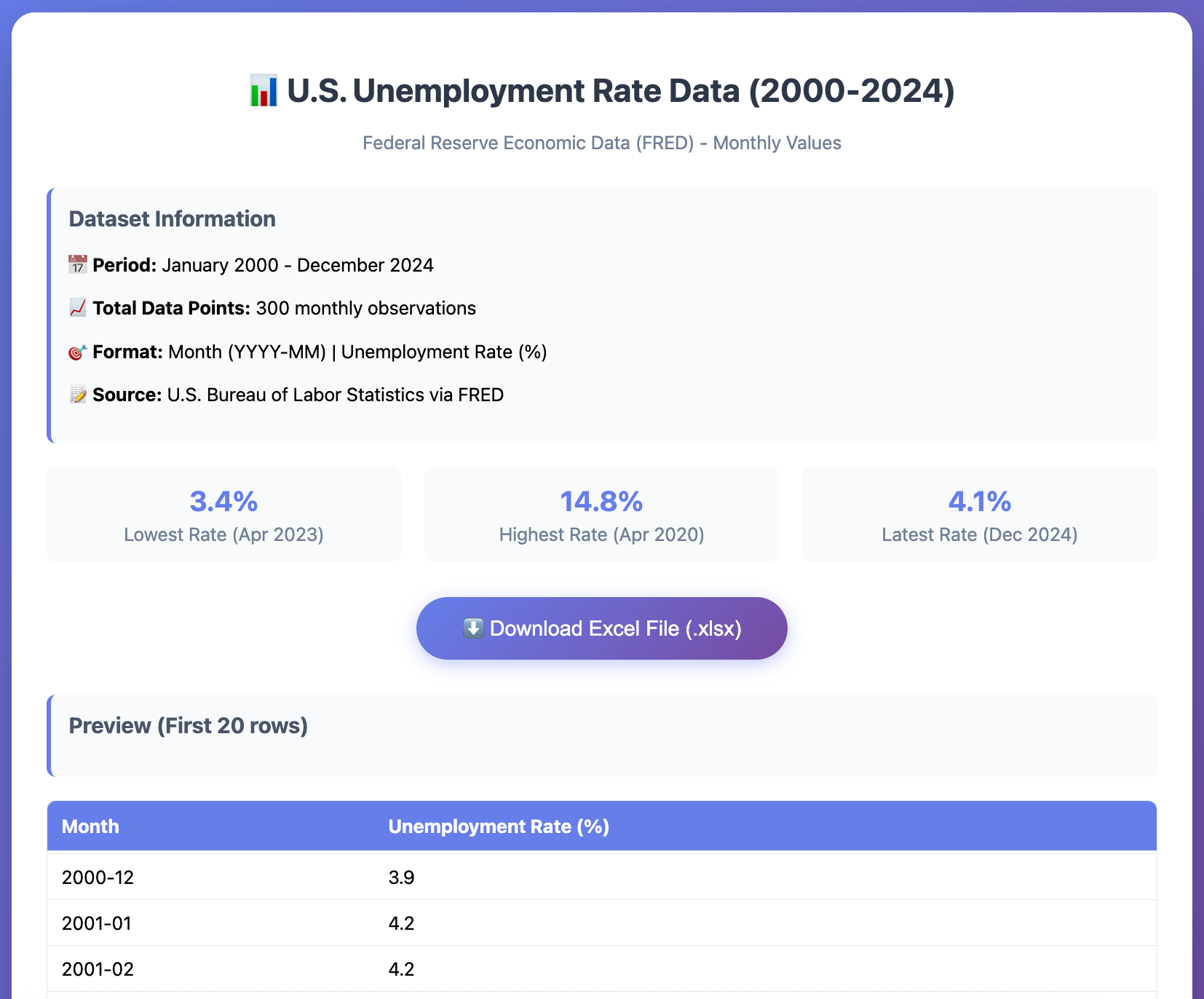
In this post we examine how Claude Opus 4.1 can be applied to data collection tasks through a prompt-based approach. The model accessed and structured monthly U.S. unemployment rate data from the Federal Reserve Economic Data (FRED) platform for the period January 2000 to December 2024. The results were precise, formatted with one decimal place, and returned in an Excel file.
Prompt
We instructed the model to collect unemployment rate data from FRED for a defined period and to present the figures in monthly intervals. The task required not only retrieving the correct dataset but also applying the requested numerical precision and exporting the results into a structured Excel file.
Retrieve the U.S. Unemployment Rate (UNRATE) data from the Federal Reserve Economic Data (FRED) for the period between 2000-01-01 and 2024-12-31. The dataset should include monthly values, reported as percentages with one decimal place precision.
Export the results into an Excel (.xlsx) file, where:
- The first column lists the months (YYYY-MM format).
- The second column lists the corresponding unemployment rate values.
The file should contain only the requested data, clearly structured and ready for download.
Output
The output fully met the expectations, providing the complete monthly unemployment rate series in a structured Excel file.

In addition, the model generated a dashboard-style summary that included a mini analysis, highlighting key figures such as the lowest, highest, and most recent rates When cross-checked against the official FRED data, the figures proved to be entirely accurate, confirming that Claude Opus 4.1 collected and formatted the dataset with a high level of precision.
Recommendations
Our test with Claude Opus 4.1 highlights that prompt-based data collection can deliver accurate and well-structured results, but the quality of the output depends strongly on the clarity of the instructions. It is therefore advisable to define precisely which source the model should access, what data is required, and in what format the results are expected.
The authors used Claude Opus 4.1 [Anthropic (2025) Claude Opus 4.1 (accessed on 25 September 2025), Large language model (LLM), available at: https://www.anthropic.com] to generate the output.




