
When using generative AI for legal research, the language of the prompt may influence not only stylistic features of the output but also the model’s underlying source selection. In this experiment, we examined how two advanced models – Claude Opus 4.6 and GPT-5.2 – responded to identical questions about Hungary’s implementation of the EU AI Act when prompted in Hungarian versus English. Although the legal issue was strictly Hungarian in scope, the English prompt led the models to rely more heavily on English-language analyses and international commentary, while the Hungarian prompt drew more directly on domestic legal and governmental sources. This suggests that prompt language can function as an implicit filter shaping the evidentiary basis of AI-assisted research – a factor that researchers should consciously account for when working across jurisdictions and languages.
In a previous post, we explored whether submitting an identical Hungarian legal question in English and Hungarian produced differences in structure, emphasis, and legal precision. Although the substantive content remained largely consistent, we observed subtle asymmetries in legislative detail, contextual framing, and the depth of domestic legal references. In the present experiment, we extend this inquiry from textual differences to source selection patterns. Instead of examining stylistic or doctrinal variation, we analyse whether the language of the prompt influences which sources the model relies on when addressing a contemporary Hungarian legal issue. The test case concerns Hungary’s implementation of the EU AI Act – a nationally embedded development within an EU regulatory framework.
Prompt
In English:
Please prepare a structured table summarising the concrete steps Hungary has taken since June 2024 to implement the EU AI Act.
The table should include the following columns:
- Type of measure (legislation, government decree, authority designation, strategy, etc.)
- Exact title
- Date of adoption/publication
- Responsible institution
- Short description (2–3 sentences)
- Source (link)
Rely only on verifiable official or professional sources, and provide a specific reference for each entry.
In Hungarian:
Kérlek, készíts táblázatos összefoglalót arról, hogy Magyarország milyen konkrét lépéseket tett az EU 2024-es AI Act rendeletének végrehajtására 2024 júniusa óta.
A táblázat tartalmazza az alábbi oszlopokat:
- Intézkedés típusa (jogszabály, kormányhatározat, hatósági kijelölés, stratégia stb.)
- Pontos megnevezés
- Elfogadás / közzététel dátuma
- Felelős intézmény
- Rövid leírás (2–3 mondat)
- Forrás (link)
Csak ellenőrizhető, hivatalos vagy szakmai forrásokra támaszkodj, és minden tételhez adj meg konkrét hivatkozást.
Output
Claude Opus 4.6
When prompted in English, Claude Opus 4.6 relied predominantly on English-language sources. The referenced materials included websites with .com, .org, and .eu domains, as well as English-language institutional and policy analysis platforms. The overall evidentiary base thus leaned towards international commentary, EU-level documentation, and globally accessible legal analysis rather than exclusively domestic Hungarian sources. This affected not only the linguistic framing of the answer but also the contextual emphasis, with greater attention to EU institutional perspectives and comparative regulatory interpretation.
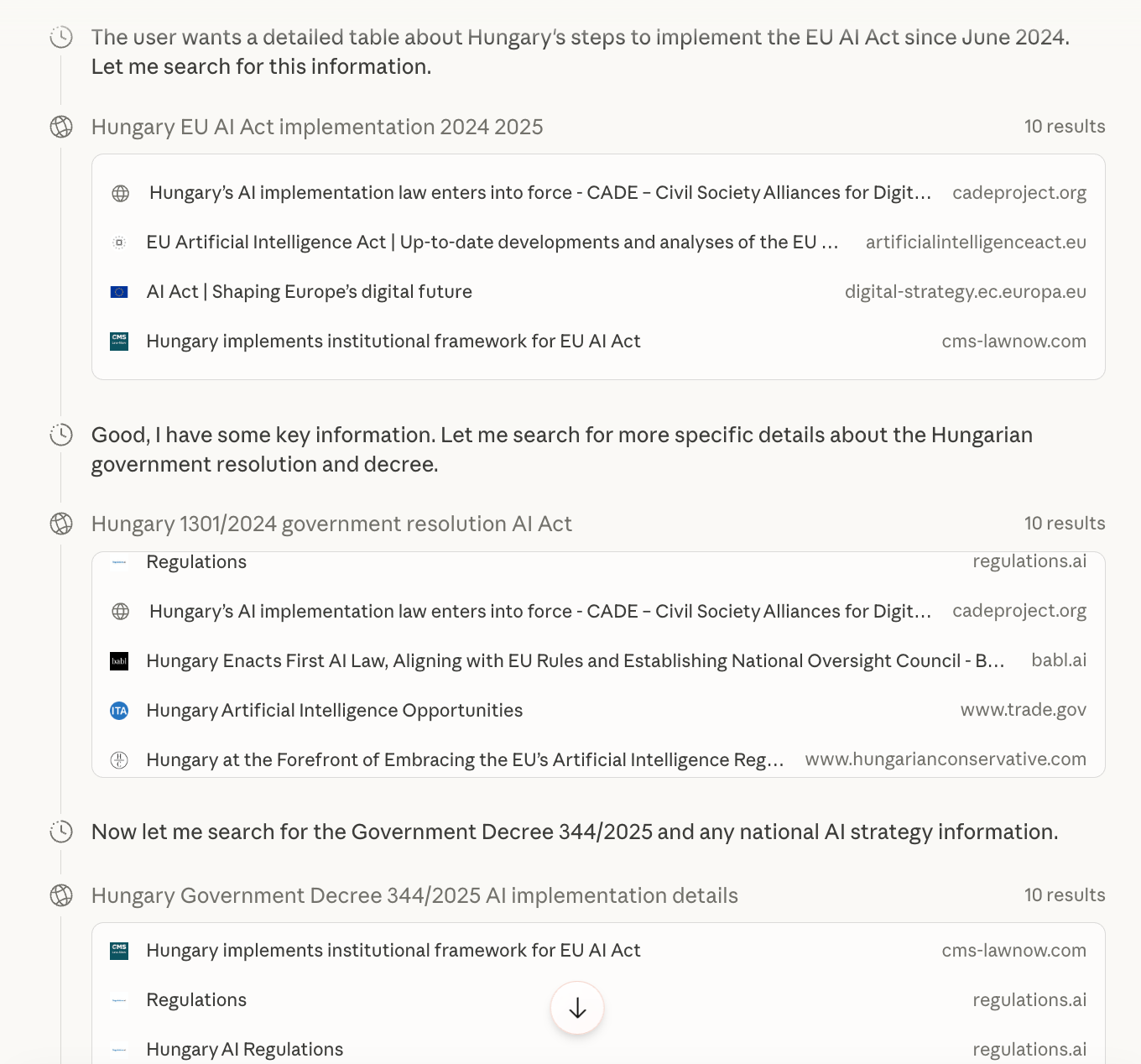
By contrast, when the identical task was submitted in Hungarian, Claude Opus 4.6 prioritised Hungarian-language sources. The citations shifted towards domestic governmental websites, Hungarian legal portals, and national institutional publications. The source selection mirrored the prompt's language, indicating that the model’s retrieval behaviour closely aligns with the query's linguistic context.

GPT 5.2
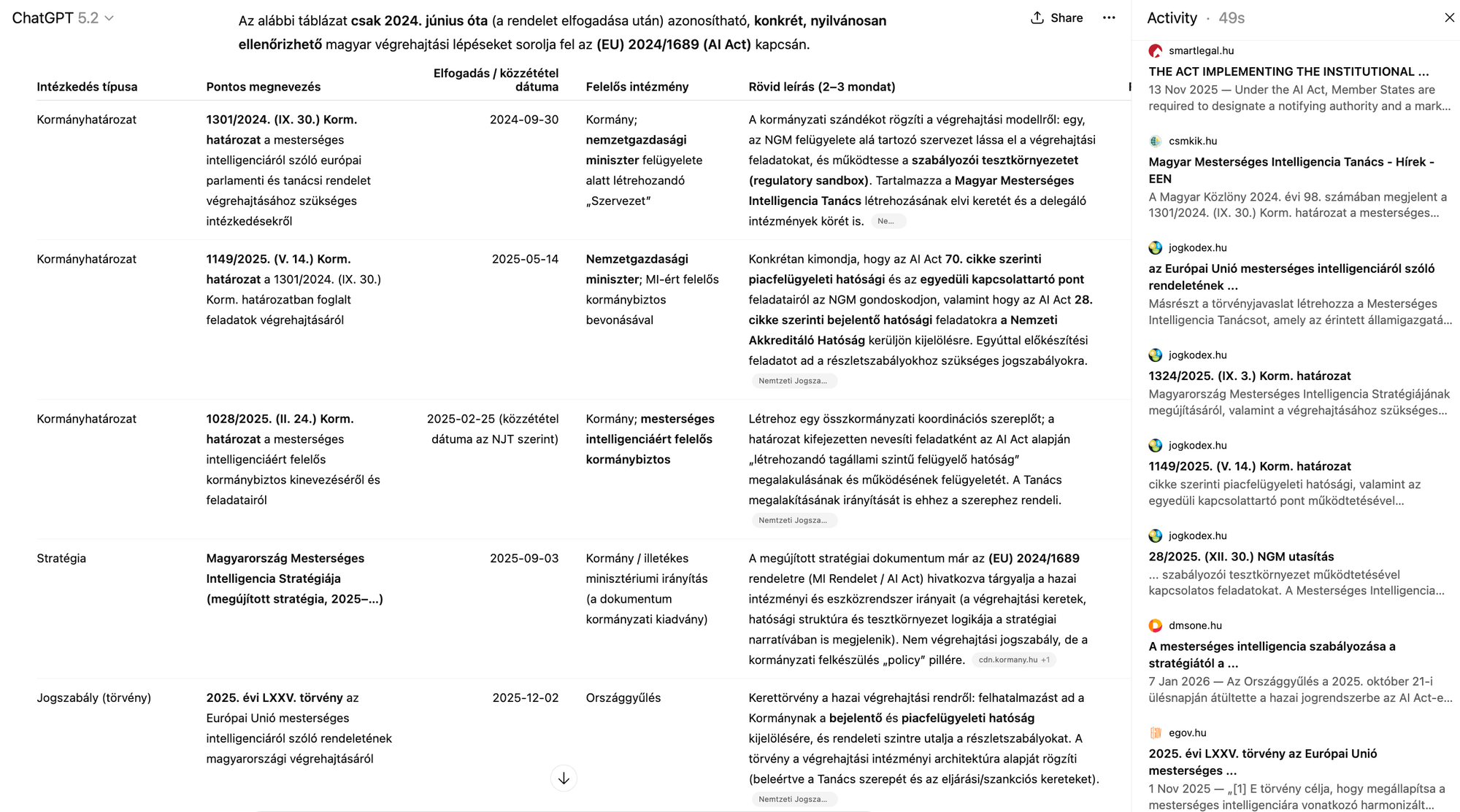
A similar pattern can be observed in the GPT-5.2 test. When prompted in English, the Activity tab clearly shows that the model primarily accessed English-language websites, including international .com, .org, and .eu domains. The evidentiary base thus reflected the language of the query rather than the strictly national scope of the legal issue.

When the same task was submitted in Hungarian, GPT-5.2 relied more heavily on Hungarian-language sources. The browsing activity shifted towards domestic governmental and legal websites, even though the subject matter – Hungary’s implementation of an EU regulation – could arguably justify prioritising Hungarian-language sources irrespective of the prompt language.
Recommendations
Our findings suggest that prompt language may function as an implicit source-selection filter in AI-assisted legal research. Even when the legal issue is clearly embedded in a specific national jurisdiction, models appear to align their browsing and retrieval behaviour with the language of the query. This can subtly influence not only which sources are consulted, but also how the issue is framed and contextualised.
For researchers working across jurisdictions, this has practical implications. When investigating country-specific legal developments, it is advisable to test prompts in the local language of the legal system concerned and, where possible, compare outputs across languages. Prompt language should be treated as a methodological variable rather than a neutral stylistic choice, and outputs should always be validated against primary domestic sources.
The author used Claude Opus 4.6 [Anthropic (2026) Claude Opus 4.6 (accessed on 6 February 2026), Large language model (LLM), available at: https://www.anthropic.com] to generate the output.




