As generative AI tools become increasingly integrated into academic practice, researchers are beginning to explore the use of Custom GPTs—personalised AI variants that operate according to predefined instructions, tone, or tasks. These agents can be configured for specific roles or workflows, such as teaching support, literature exploration, or data analysis. However, their academic value varies widely: while some offer useful starting points for domain-specific assistance, many remain experimental, unverified, or too general for reliable research use. This blog post provides an overview of what Custom GPTs are, how they differ from the default interface, and where they might (and might not) support academic work. In a follow-up post, we will explain how to create and configure one in practice.
Finding and Exploring Custom GPTs in the GPT Store
Custom GPTs are accessible to both free and Plus users within the ChatGPT interface. On the left-hand sidebar, you’ll find the “Explore GPTs” button beneath the main chat area. This opens the GPT Store—a searchable interface where users can browse, test, and favourite a wide range of pre-built assistants created by OpenAI and the broader community.
Within the GPT Store, users can also explore assistants organised by thematic categories such as “Research & Analysis” or “Education”. These labels help identify GPTs specifically designed for academic use—whether for literature summarisation, citation formatting, data inspection, or classroom assistance.

Putting Scholar GPT to the Test: Literature Review Performance Falls Short
Among the many academic-themed Custom GPTs, Scholar GPT is one of the most visible examples designed specifically for researchers and students. It presents itself as a general-purpose assistant for academic tasks such as summarising articles, generating citations, or exploring scholarly debates. It uses a formal tone, encourages citation formatting, and often mimics the structure of academic writing.
However, despite these promising features, Scholar GPT lacks access to verified academic databases and does not cite real sources unless manually provided. It may fabricate references or misrepresent key findings—limitations common to many large language models. While it can help draft outlines or explore how a literature review might be structured, any content it generates should be treated as a preliminary draft and subjected to rigorous fact-checking before inclusion in scholarly work.
To assess the capabilities of Scholar GPT in an authentic academic scenario, we submitted a structured prompt requesting a 1,500-word literature review on the Comparative Agendas Project (CAP), with a formal tone, Harvard-style citations, and a dedicated section on the Hungarian CAP. The task was framed according to standard expectations in thesis-level social science writing: theoretical framing, methodological overview, cross-national empirical examples, and critical reflection.
Prompt
Please write a 1,500-word literature review on the Comparative Agendas Project.
Focus on key academic contributions, theoretical debates, and methodological developments related to the project.
Include references to landmark publications, highlight its relevance in comparative policy analysis, and outline how it has been used in empirical research.
Use Harvard-style in-text citations, UK spelling, and an academic tone appropriate for inclusion in a journal article or thesis chapter.
Please include a separate section that discusses the Hungarian Comparative Agendas Project, including its scope, national adaptations, and key findings or publications.
Output
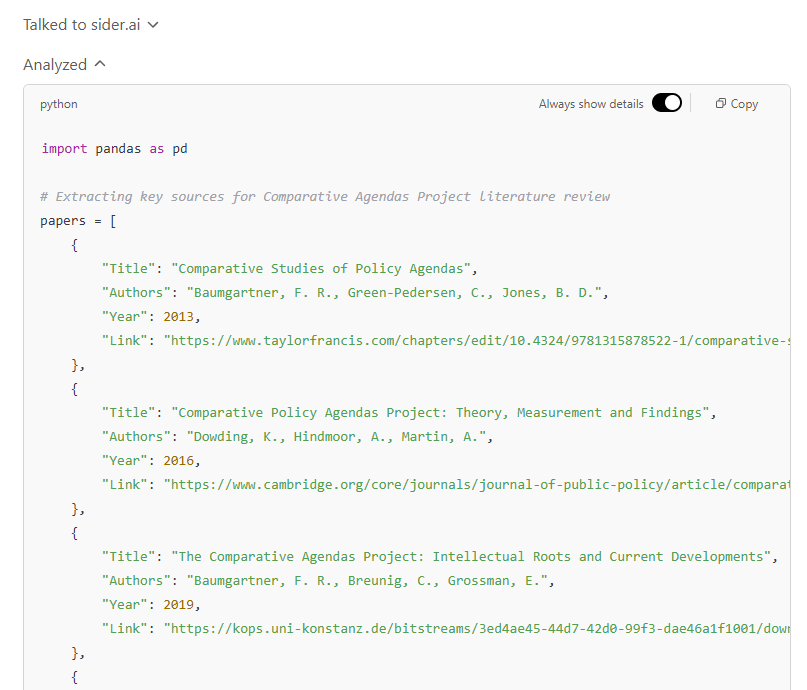
Instead of generating a cohesive literature review, the model returned a loosely structured list of nine academic references—some tangentially relevant, others of unclear connection to the Comparative Agendas Project. Crucially, even basic bibliographic details proved unreliable: the very first entry (Comparative Studies of Policy Agendas) was incorrectly dated as 2013, although it was published in 2008. While the table format was visually neat, the model ultimately failed to deliver the requested literature review. No structured text, analytical narrative, or integrative discussion was produced—only a loosely compiled list of sources with minimal contextualization.

SciSpace in Practice: Informative, But Not a Literature Review
Following our experiment with Scholar GPT, we turned to SciSpace—a widely promoted academic assistant that promises structured literature support. Using the same prompt (requesting a 1,500-word literature review on the Comparative Agendas Project with Harvard in-text citations), we assessed whether SciSpace could better meet the standards of scholarly writing.
Although this time the model did return a continuous written response — unlike Scholar GPT, which failed to produce any extended text — the result still fell short of expectations for an academic literature review. Most notably, instead of using Harvard-style in-text citations and referencing peer-reviewed publications, the response relied almost entirely on content from the Hungarian CAP project’s public website, embedding direct links rather than citing formal sources. The output resembled a general project overview more than a critical synthesis of the academic literature.

Recommendations
While Custom GPTs offer potential support for academic tasks, our tests show that many are not yet reliable for research purposes. Issues such as inaccurate references, lack of citation standards, and overreliance on non-scholarly sources are common. These tools may assist with outlining or exploring topics, but their outputs should always be treated as drafts and carefully fact-checked before use in scholarly work. Until better integration with verified academic sources is available, Custom GPTs remain experimental aids—not substitutes for academic rigour.
The authors used GPT-4o [OpenAI (2025) GPT-4o (accessed on 29 April 2025), Large language model (LLM), available at: https://openai.com] to generate the output.




