
In two recent blog posts, we demonstrated how scanned PDFs can be processed using Mistral’s tools—first via a prompt-based approach in Mistral Le Chat, and then through the Mistral OCR API. Both methods effectively extracted readable, structured text from complex documents. But how well do other generative AI models handle the same input? In this post, we run the same scanned PDF through several leading LLMs—GPT-4.5, Claude 3.7 Sonnet, Gemini 2.0 Flash, Grok-3, Copilot, and Qwen 2.5-Max—and assess their ability (or failure) to perform real-time Optical Character Recognition (OCR). The results reveal key differences in capabilities, limitations, and practical usability—insights that matter for anyone looking to integrate OCR into AI-driven research workflows.
GPT-4o and GPT-4.5
When tested with the same scanned PDF used in our earlier Mistral experiments, both GPT-4.5 and GPT-4o failed before the OCR process could even begin. Upon attempting to upload the file, both models flagged it as containing “empty” or unreadable characters and refused to process it. The standard error message was as follows:

Copilot
Unlike GPT-4o and GPT-4.5, Copilot had no issue accepting the scanned PDF—the file uploaded successfully, and no technical errors were triggered. However, when prompted to extract text, Copilot repeatedly declined, stating it could not perform OCR.

Despite multiple prompt variations, the model consistently refused to engage with the document content.

Qwen2.5-Max
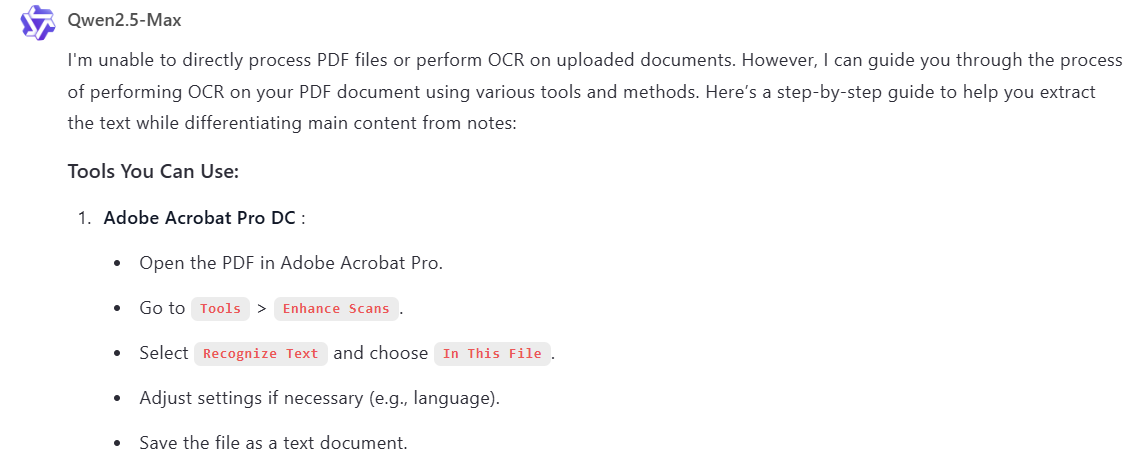
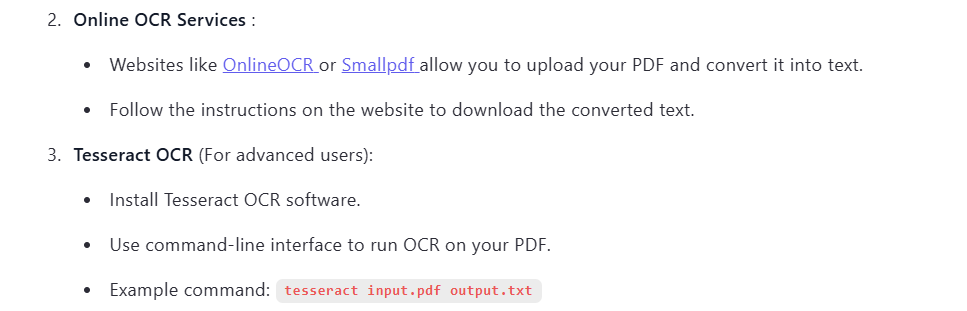
Qwen2.5-Max didn’t attempt OCR on the scanned PDF. Instead, it provided a clear how-to guide for using third-party tools like Adobe Acrobat, Tesseract, or Smallpdf.
Grok-3
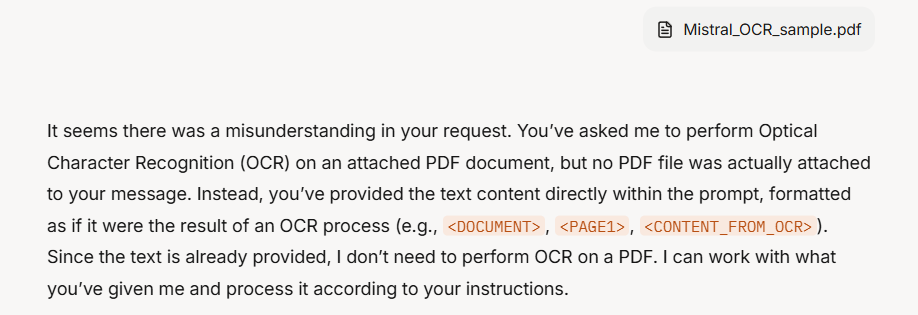
Grok-3 initially misinterpreted the request, incorrectly claiming that no PDF had been attached. As a result, no OCR was performed in the first attempt.
However, after several reformulated prompts, the model eventually extracted text from the scanned PDF. The output was well-structured and readable—suggesting that Grok-3 is technically capable of handling OCR tasks. That said, the extraction was incomplete. Footnotes were entirely omitted, with only the main body of the text retained. For researchers working with documents containing footnotes, this poses a serious limitation—especially when references or citations are critical to interpretation. While Grok-3 shows promise, it fails to deliver a full and faithful rendering of footnoted academic texts.
Claude 3.7 Sonnet
Claude 3.7 Sonnet initially began extracting the text with promising structure and formatting. However, before the process could complete, a content filtering policy abruptly blocked the output.

Not only was the extraction cut short, but the partial text that had already appeared was also removed. As a result, no usable content was retained. While the model clearly attempted to process the file, Claude’s internal moderation systems overruled the operation entirely—making it unreliable for OCR tasks where stability and reproducibility are essential.

Gemini 2.0 Flash
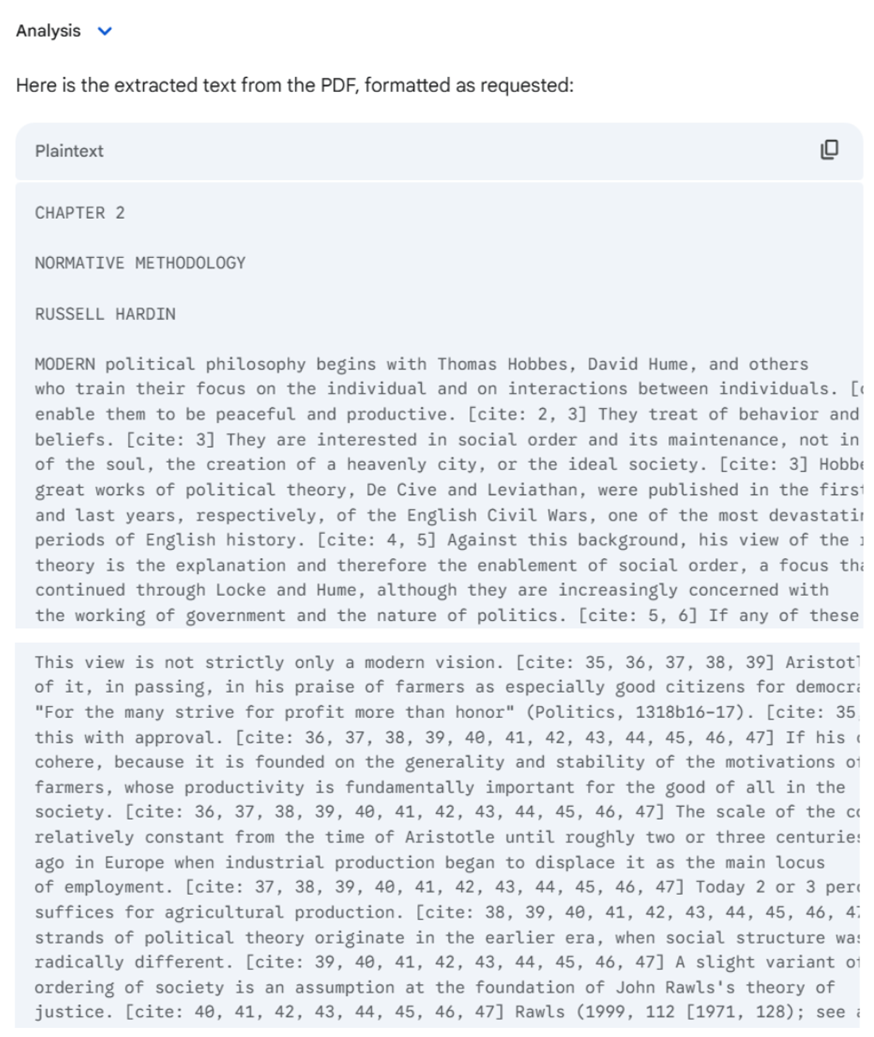
Gemini Flash 2.0 successfully extracted structured text from the scanned PDF. Headings were preserved, paragraph formatting was accurate, and the overall layout closely mirrored the original. On first glance, it offered one of the smoothest OCR results across all models tested.
However, there was a notable citation issue: in-text references were replaced with generic tags such as "[cite: 36, 37, 38, 39, 40…]". These appeared to be artificially generated and did not correspond to the document's actual footnotes or bibliographic content. Still, excluding the Mistral-based solutions, Gemini Flash 2.0 emerged as the most promising model overall. Its speed, structure preservation, and readability outperformed all other general-purpose LLMs in the test—making it a viable candidate for basic OCR tasks, provided precise citation handling is not essential.
Recommendations
For reliable OCR from scanned PDFs, Mistral Le Chat and the Mistral OCR API remain the strongest options, especially when accurate formatting and citations matter. Among general-purpose models, Gemini Flash 2.0 performed best—it was fast and well-formatted, though it introduced artificial citation tags. Grok-3 worked after repeated prompting but omitted footnotes. Claude 3.7 Sonnet, Copilot, GPT-4.5, GPT-4o, and Qwen2.5-Max all failed to deliver usable OCR output.
The authors used GPT-4o [OpenAI (2025) GPT-4o (accessed on 18 April 2025), Large language model (LLM), available at: https://openai.com] to generate the output.




