
Large language models (LLMs) rely on a set of parameters that directly influence how text is generated — affecting randomness, repetition, length, and coherence. Understanding of these parameters is essential when working with LLMs in research, application development, or evaluation settings. While chat-based interfaces such as ChatGPT, Copilot, or Gemini typically hide these settings from users, full control over generation parameters is available through APIs (e.g. OpenAI), developer libraries like Hugging Face Transformers, or local inference platforms such as Text Generation WebUI or LM Studio. In these environments, adjusting parameters such as temperature, top_k, top_p, max_tokens, seed, or mirostat can significantly influence the quality, consistency, and diversity of the generated output. This guide outlines each of these parameters, how they work individually and in combination, and what practical and theoretical considerations apply when tuning them.
Large language models generate text by sampling from a probability distribution over tokens predicted at each step. Several hyperparameters influence how this sampling unfolds to achieve the desired trade-offs among diversity, coherence, and relevance. These include: temperature, top_k, top_p (nucleus sampling), max_tokens, seed, stop sequences, context length, frequency penalty, repeat last N, batch size, and additional adaptive or specialised parameters such as mirostat (with its own mirostat_tau and mirostat_eta), tfs_z, and num_keep (the number of tokens to keep on context refresh). Each parameter influences the probability distribution before or during the sampling process, and their settings have direct mathematical and empirical effects on generated text quality. Effective control over output quality in LLMs typically requires joint tuning of multiple parameters, given their overlapping and interacting effects on generation dynamics.
1. Temperature
Temperature is applied to scale the raw logits output by the model before converting them to probabilities via the softmax function. Mathematically, given a raw logit u_l for each token l, the probability p(l) is computed as
$$
p(l) = \frac{\exp\left(\frac{u_l}{T}\right)}{\sum_i \exp\left(\frac{u_i}{T}\right)}
$$
A lower temperature (T < 1) sharpens the distribution, increasing the probability mass on high-probability tokens and effectively making the output more deterministic and focused; however, it risks causing repetitive or overly bland text. Conversely, a higher temperature (T > 1) flattens the probability distribution, increasing diversity but potentially reducing coherence due to the inclusion of lower-probability (or “improper”) tokens.
To illustrate how temperature influences model behaviour, we used the OpenAI GPT-4.1 model via the OpenAI API. Our test question was: “Why do researchers use control groups in experiments?” We submitted this same prompt multiple times while varying the temperature parameter (e.g., 0.1 vs. 1.4) to observe determinism and response diversity differences.
When the temperature was set to 0.1, the responses generated by the model were virtually identical. Both answers offered a clear, textbook-style explanation.

In contrast, with a temperature of 1.4, the responses became more diverse and expressive. While the core idea remained the same — emphasising the function of control groups in experimental design — the wording was more elaborate, and the structure varied noticeably. One response even introduced broader reflections on “psychological forces” and “pinpoint accuracy,” showing how higher temperature encourages more creative, less constrained language generation, albeit with a potential trade-off in clarity or conciseness.

At a temperature of 2.0, the model produced incoherent and nonsensical output. This is due to the extreme flattening of the probability distribution, which gives unlikely tokens too much weight. While higher temperatures can enhance creativity, values this high typically degrade relevance and coherence. For most practical use cases, such settings should be avoided.

2. Top K
Top_K sampling limits the model’s choices to the k most probable tokens and renormalises the distribution over this restricted set. This helps eliminate unlikely options and ensures more controlled, coherent output. Mathematically, if only the top_k probabilities are retained, sampling follows:
$$
p_k(l) = \frac{p(l)}{\sum_{i \in \text{top}{k}} p(i)}, \quad \text{for } l \text{ in the set of top } k \text{ tokens}.
$$
This method is particularly useful when one wants to maintain a cap on the candidate pool, avoiding the influence of very low probability tokens. However, choosing a fixed k can be problematic in cases where the underlying distribution is highly dynamic across different contexts.
3. Top_p (Nucleus Sampling)
Rather than fixing the number of tokens as with top_k, nucleus sampling involves choosing the smallest set of tokens whose cumulative probability exceeds a threshold p. In effect, the candidate set is dynamic and adapts to the shape of the probability distribution. This method usually yields a more context-sensitive candidate pool that balances diversity and quality. It thereby tends to produce outputs that are closer in perplexity to human text because it naturally adapts to model certainty.
4. Max_tokens
This parameter sets the upper bound on the length of the generated sequence. It essentially serves as a hard cut-off for how long the generation process continues, thereby controlling computational cost and ensuring that output does not run indefinitely. Though it does not affect the distribution at each step, it influences the global structure and coherence over longer sequences.
5. Seed
The seed parameter fixes the starting point for the pseudorandom number generator used during token sampling. It does not change the underlying probabilities but guarantees the reproducibility of generated outputs when other parameters remain fixed. This is critical in research comparisons and any production use case requiring deterministic outputs.
6. Stop Sequences
Stop sequences are predetermined token strings which, when encountered during generation, signal the system to terminate the process. They provide an external boundary that ensures the output conforms to specific formatting or content boundaries, such as sentence or paragraph endings. This parameter is independent of the probabilistic framework but affects the final length and the completeness of generated content.
7. Context Length
Context length refers to the number of tokens the model considers as context when generating new tokens. A longer context length allows the model to take more historical information into account, thereby maintaining better coherence over long passages. However, it also increases computational demands and may necessitate truncation methods (e.g. num_keep) to manage memory and efficiency.
8. Frequency Penalty
Frequency penalty modulates the generation by reducing the probability of tokens already appearing in the output. Mathematically, it applies a penalty (often a negative bias) to the original logit scores of frequent tokens, thereby discouraging repetition. It is especially useful when the objective is to minimise redundancy without completely excluding repeated tokens.
9. Repeat Last N
This parameter prevents the model from generating tokens that have appeared in the most recent N tokens, acting as a hard constraint to combat immediate repetition. It is functionally similar to a frequency penalty but works in a localised and often stricter manner. Because its scope is limited to the immediate past, it complements global frequency penalties yet may be redundant if applied too aggressively.
10. Batch Size
Batch size determines how many separate sequences are generated concurrently. Although it does not directly influence the probability distribution per token, it has implications for computational efficiency, throughput, and variability across generated outputs if combined with techniques like multi-sample inference or majority voting.
11. Mirostat, mirostat_tau, mirostat_eta
Mirostat is an adaptive decoding algorithm that seeks to maintain a target perplexity or level of “surprise” (average token-level cross-entropy) throughout generation. Unlike fixed parameters like temperature, mirostat adjusts the effective sampling cutoff (often via an adaptive top_k mechanism) to dynamically match a pre–specified target (mirostat_tau) using a learning rate (mirostat_eta). Mathematically, it utilises feedback from the observed token surprise to update the sampling parameters so that the perplexity remains near the target value, thereby balancing diversity and coherence dynamically over long outputs.
12. Tfs_z
Tfs_z stands for the tunable parameter in tail-free sampling methods. It helps filter the candidate tokens based on the curvature or derivative of the sorted probability distribution. This parameter removes tokens that lie in the extreme tail of the probability distribution – essentially those that are “atypical” – which can further refine the quality of generated samples. It is often used with other truncation mechanisms like top_p and top_k, contributing additional fine-grained control.
13. Num_keep (tokens to keep on context refresh)
In scenarios where the context window is refreshed or truncated to manage computational load, num_keep specifies the number of tokens from the previous context that should be retained. This parameter is crucial for maintaining continuity and coherence in long-form generation, as preserving a fixed part of the history ensures that the model has access to important earlier content even when the overall context is constrained.
Interdependencies Among Decoding Parameters
Temperature, Top_k, Top_p and Seed
Temperature, top_k, and top_p jointly determine how the model samples from its probability distribution during text generation. Temperature sets the overall sharpness of the distribution: lower values make the output more deterministic, while higher values increase randomness and creativity. Top_k and top_p then restrict the candidate pool of tokens: top_k limits it to the k most probable tokens, while top_p includes only the smallest set of tokens whose cumulative probability exceeds the threshold p. These methods are often used together to shape both the output's diversity and relevance.
The seed parameter complements this setup by controlling the reproducibility of the sampling process. While it does not alter the underlying distribution, a fixed seed ensures that repeated runs with the same settings (temperature, top_k, and top_p) will produce identical outputs. The outputs will vary due to stochastic sampling if the seed is changed or omitted. In this sense, seed interacts with the other parameters by determining whether the randomness introduced through them leads to consistent or variable results.
Parameter Configuration in Practice: A Comparative Example
To demonstrate how decoding parameters interact in practice, we prompted a model with the question: “Who developed both the special and general theories of relativity?” We then compared the outputs under two different parameter configurations, using the Qwen-32b model via a GUI interface that allows full manual control.
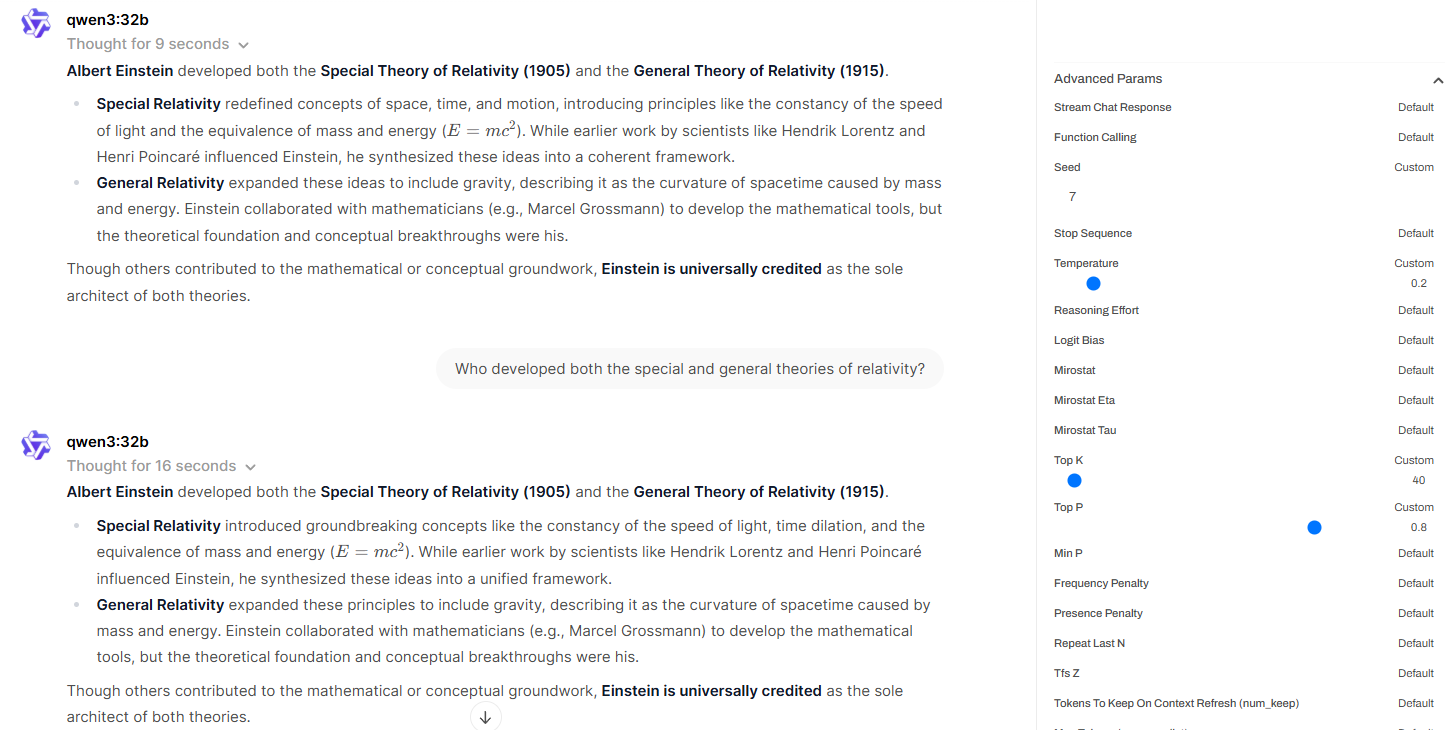
First Configuration (Temperature: 0.2, Top_k: 40, Top_p: 0.8, Seed: 7)
The model responded concisely and consistently across runs. The answers were brief, factual, and aligned with the instruction to provide no more than three sentences. This reflects the combined effect of a low temperature (which sharpens the probability distribution), a constrained top_k (limiting token diversity), and a mid-range top_p (ensuring cumulative probability remains focused). The fixed seed further enhanced reproducibility. Together, these settings promote high determinism and instruction-following behaviour.
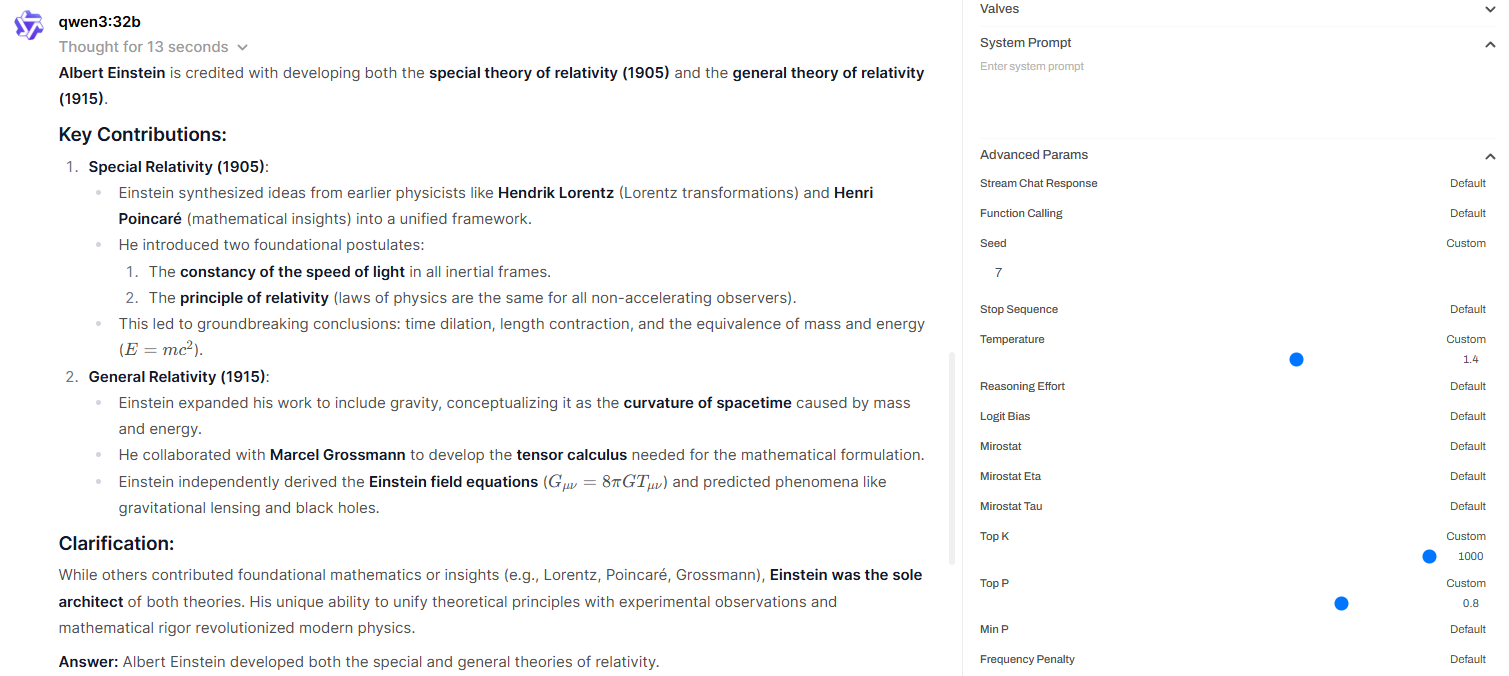
Second Configuration (Temperature: 1.4, Top_k: 1000, Top_p: 0.8, Seed: 7)
Despite the same prompt, the model produced much longer and more elaborate responses. The high temperature flattened the distribution, increasing randomness, while the large top_k expanded the sampling space to include many low-probability tokens. Even though top_p remained moderate, it could not offset the effects of the high temperature and wide top_k. As a result, the model became verbose and less compliant with the original instruction—demonstrating how overly permissive settings can reduce controllability, even with a fixed seed.
Recommendations
When tuning decoding parameters in large language models, we recommend starting with conservative values prioritising coherence and instruction-following, particularly in research or production contexts. A temperature between 0.2 and 0.7 typically yields reliable, relevant output. Combining this with a moderate top_k (e.g., 40–100) and a top_p value around 0.8 offers a balanced trade-off between determinism and diversity. For reproducibility, always fix the seed when comparing outputs.
Avoid extreme settings — such as a temperature above 1.5 or top_k values in the thousands — unless your goal is explicitly to generate highly creative or unpredictable text. These can lead to verbosity, incoherence, or even meaningless output. Finally, parameters should always be evaluated in combination, as their effects are interdependent and context-sensitive.
The authors used GPT-4o [OpenAI (2025), GPT-4o (accessed on 26 May 2025), Large language model (LLM), available at: https://openai.com] to generate the output.




