
Recent advances in open-weight large language models have made it possible to run powerful AI tools entirely on local machines. In this article, we outline how researchers can set up and interact with models such as Deepseek, Mistral, or Llama using Ollama for local model management and Open WebUI for a convenient browser-based interface. We provide step-by-step instructions for environment setup, model selection, and web-based interaction, enabling private, flexible experimentation without the need for cloud services or programming expertise. Key limitations—including hardware requirements, resource usage, and current model capabilities—are also discussed.
Why Run LLMs Locally?
Running open-weight large language models locally provides researchers with enhanced data privacy and direct control over their experimental environment. This setup ensures that all computations remain on the user’s own hardware, safeguarding sensitive data while enabling fully reproducible workflows independent of external service providers. Local deployment further allows for flexible model selection and configuration, making it possible to tailor the system precisely to specific research needs.
Necessary Tools and Resources
To deploy and interact with large language models locally via Ollama and Open WebUI, the following components are required:
- Workstation or laptop running Windows, macOS, or Linux, equipped with at least 8–16 GB of RAM and sufficient storage capacity;
- Docker (for container management): Download Docker Desktop;
- Ollama (for model orchestration and local inference): Download Ollama;
- One or more open-weight language model files (e.g. Mistral, DeepSeek R1, or other supported GGUF models):
- Up-to-date web browser (for accessing the Open WebUI interface): e.g. Chrome, Firefox, Edge, or Safari;
- Optional: NVIDIA GPU with compatible drivers for accelerated inference
If you wish to leverage GPU acceleration (supported mainly on Linux systems), ensure that you have the latest NVIDIA drivers and the NVIDIA Container Toolkit installed: NVIDIA Driver Downloads.
Step-by-Step Installation and Setup
This section provides concrete terminal commands for installing and running Ollama and Open WebUI, based on our hands-on experience.
- Install Docker
Download and install Docker Desktop corresponding to the system’s operating environment. After installation, verify Docker is working by running the following command in the terminal:
docker --version
The Docker version information should appear as output.
2. Install Ollama
Download the Ollama installer suitable for the operating system from the official website. Once the installation is complete, verify that Ollama is available by entering the following command in the terminal:
ollama --version
If the installation was successful, the command will display the Ollama version information.
- Installing and Launching Open WebUI
Once Docker and Ollama are installed and verified, the next step is to deploy a user-friendly web interface for local model interaction. Open WebUI provides a browser-based environment for managing models and running inference conveniently. In the terminal, run:
docker run -d \
-p 3000:8080 \
-e 'OLLAMA_BASE_URL=http://host.docker.internal:11434' \
--name open-webui \
--restart unless-stopped \
ghcr.io/open-webui/open-webui:main
This command launches Open WebUI as a background service, accessible via your web browser at the specified host address. Ensure that Docker Desktop is running before executing this command. If the container name is already in use, remove the previous instance with docker rm -f open-webui before repeating the command.
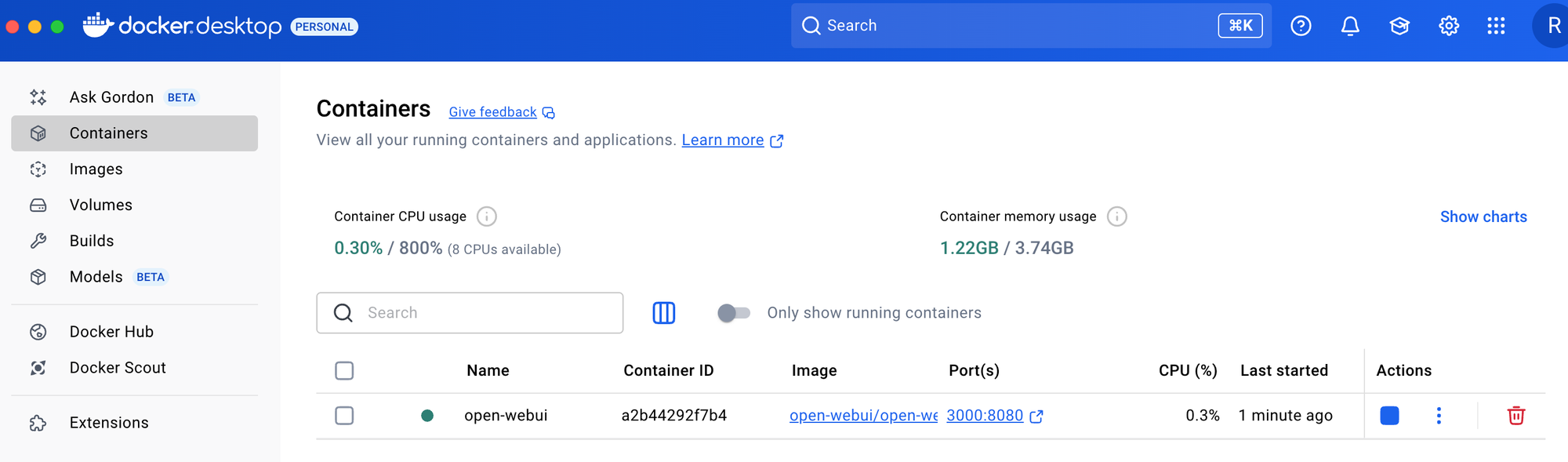
- Pulling and Managing Models in Ollama
With the backend running, you can now download and manage models locally using Ollama. For instance, to pull the Mistral or DeepSeek model, run in the terminal:
ollama pull mistral:7b
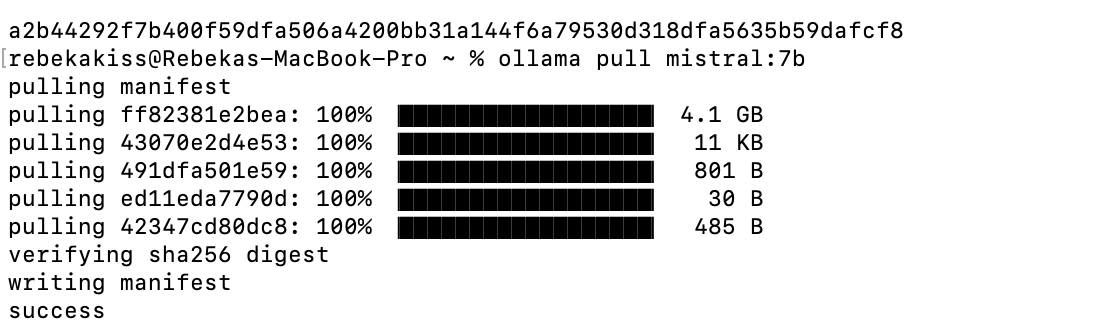
or
ollama pull deepseek:1.5b

or
ollama pull qwen3:4b
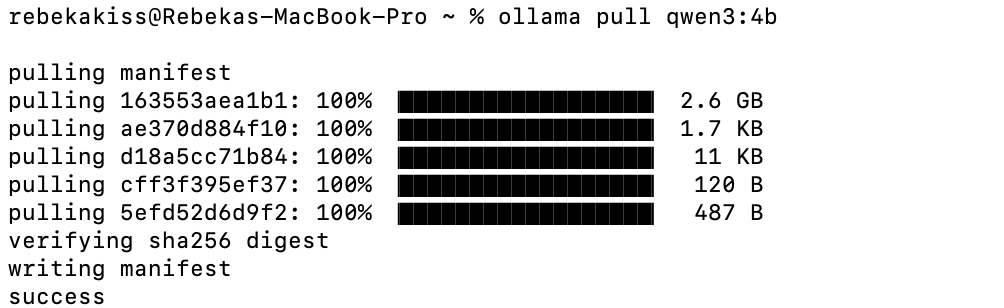
Once downloaded, these models become available both through the terminal and the Open WebUI interface:
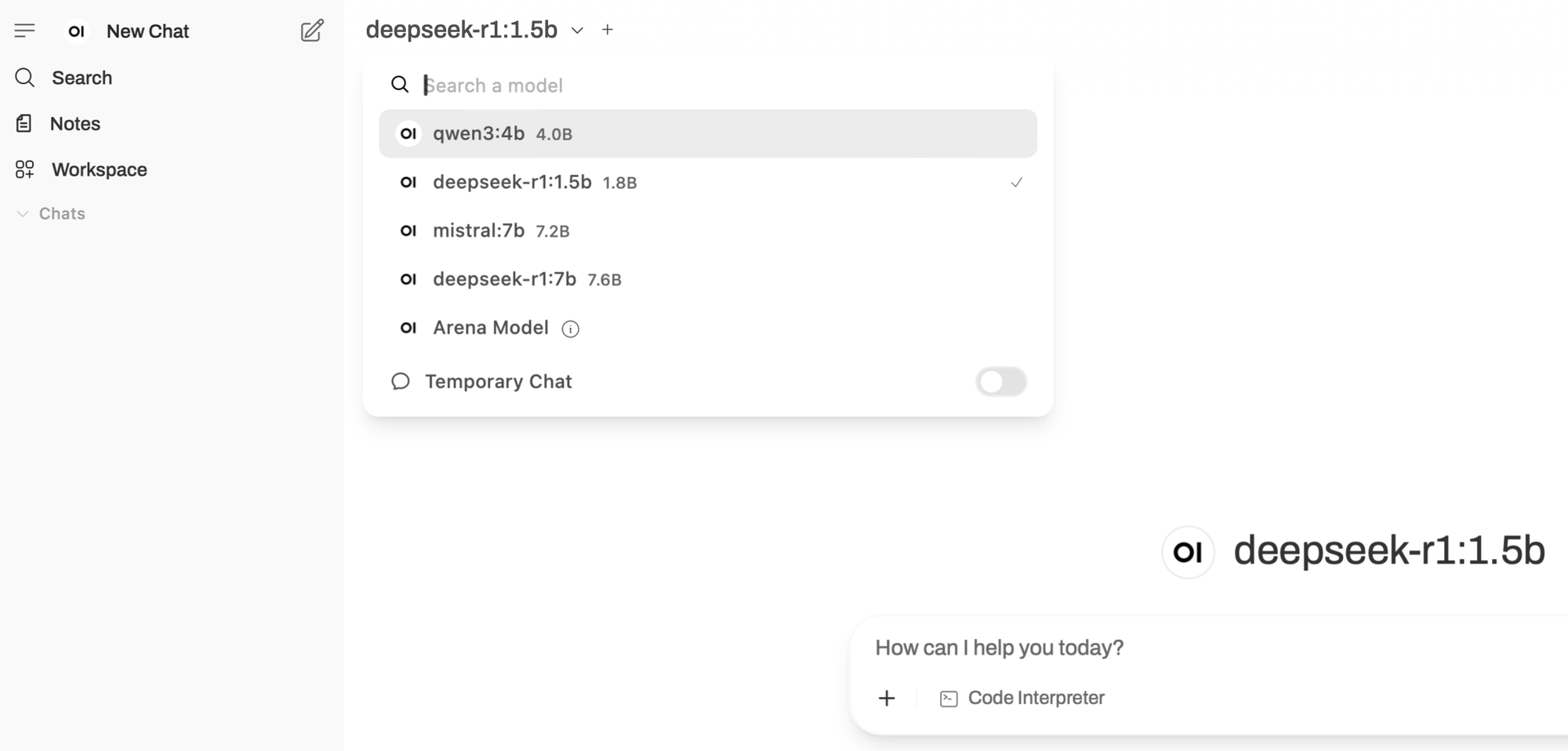
5. Accessing the Open WebUI Interface
Open your preferred web browser and navigate to the address specified when launching the Open WebUI container (typically shown in the Docker dashboard or terminal output). The Open WebUI dashboard allows you to select, configure, and interact with your chosen language models directly within the browser—supporting prompt entry, response review, and model management, all via an intuitive graphical interface.

- Removing Unused Models
Over time, you may accumulate language models that are no longer required for your research or experimentation. To free up disk space and maintain an organised environment, unwanted models can be removed via the terminal using Ollama’s command-line interface. The following command deletes a specified model from the local repository:
ollama rm 'model-name'
Replace 'model-name' with the exact name of the model you wish to remove (for example, mistral:7b or deepseek-r1:1.5b).
You can list all available models with:
ollama list
- Limitations and Practical Considerations
While recent advances in model distillation have made it feasible to run powerful language models on local hardware, significant practical differences remain between models—both in terms of computational requirements and real-world usability. For example, DeepSeek’s “distilled” R1 model, DeepSeek-R1-0528-Qwen3-8B, is frequently advertised as being capable of running on a single GPU. However, in practice, the resources required even for such “smaller” models can be substantial:
- Distilled Model Advantages and Trade-offs:
Distilled models reduce computational demands and enable deployment on less specialised hardware. However, they generally provide lower reasoning ability, shorter context windows, and less robust performance than their larger counterparts. - Desktop Feasibility:
On typical consumer machines, only compact models will run efficiently; larger models either fail to load or produce extremely slow responses. For example, attempting to load an 8B parameter model on a machine with 8 GB of RAM is unlikely to succeed. - Performance vs. Accessibility:
Recent distilled models—such as DeepSeek-R1-0528-Qwen3-8B—may surpass competitors in certain tasks, but the practical ability to use these models locally remains strictly determined by available system resources. - Model Licensing:
Most distilled models are released under permissive licences (e.g. MIT), allowing unrestricted use in academic and commercial projects.
Recommendations
When running large language models locally, carefully consider both the intended application and the hardware resources available. For exploratory experimentation, small to medium models—such as Mistral 7B, Qwen3 4B, or DeepSeek-R1-1.5B—generally offer the best balance between performance and accessibility on standard desktops or laptops. Users seeking more advanced reasoning or longer context windows may require dedicated high-memory GPUs and should anticipate increased resource usage. For reproducible research and maximum data privacy, always prefer local deployment over cloud-based inference whenever feasible. Regularly review and remove unused models to conserve storage, and consult official documentation for each model regarding licensing and permitted use cases.
The authors used DeepSeek-R1 [DeepSeek (2025) DeepSeek-R1 (accessed on 30 May 2025), Large language model (LLM), available at: https://www.deepseek.com] to generate the output.




