
Mistral’s GenAI capabilities make extracting text from scanned documents remarkably easy without relying on traditional OCR software. In this post, we demonstrate how scanned PDFs can be processed directly through a prompt-based interaction using Mistral Le Chat—producing clean, editable .txt outputs with minimal effort.
Input file
We tested how well Mistral’s Le Chat interface could handle text extraction based solely on a detailed prompt. We used a 10–12 page scanned PDF containing structured academic content, including headings and footnotes—typical of a research paper or book chapter. Instead of using a dedicated OCR tool, we uploaded the unprocessed scanned file to Mistral Le Chat and asked the model to extract the text directly. The prompt guided the model to produce a clean and readable .txt file, while preserving the document’s structure.
Prompt
📄 OCR Task – Structured PDF Text Extraction
Please perform Optical Character Recognition (OCR) on the attached PDF document to extract all textual content. The document is approximately 10–12 pages long. It is essential to ensure that the main text and any notes are clearly differentiated in the output.
Text Extraction:
- Extract the entire textual content from each page of the PDF.
- Maintain the original structure and formatting of the text, including headings, paragraphs, lists, and any other textual elements.
Note Identification:
- Identify and extract any notes or annotations present in the document. These may include handwritten notes in the margins, typed comments, or any additional text that is not part of the main content.
- Clearly differentiate these notes from the main text. Use a consistent method to mark notes, such as enclosing them within square brackets [like this] or using a different font style.
Output Format:
- Save the extracted text in a plain text file (.txt).
- Ensure that the text is easily readable and editable.
- If the PDF contains images or diagrams that are essential to understanding the text, briefly describe them in the output.
Accuracy and Completeness:
- Ensure that the OCR process captures all text accurately, including any special characters or symbols.
- Verify that no text is omitted, especially from notes or annotations, which might be smaller or less prominent than the main text.
File Naming:
- Name the output text file in a way that reflects the content or purpose of the document, making it easy to identify later.
Please process the PDF according to these detailed instructions and provide the complete text output in a downloadable .txt file.
Output
The extraction process using Mistral’s Le Chat took under five minutes. Throughout this time, the interface transparently displayed each step—from rendering the textual content to generating the final Python snippet that saved the output to a .txt file. Once completed, the result was presented as a downloadable plain text file (extracted_text.txt), ready for further use. The clarity of the process and the structured output make this approach especially appealing for users seeking a quick and accessible solution without needing to set up a full OCR pipeline.
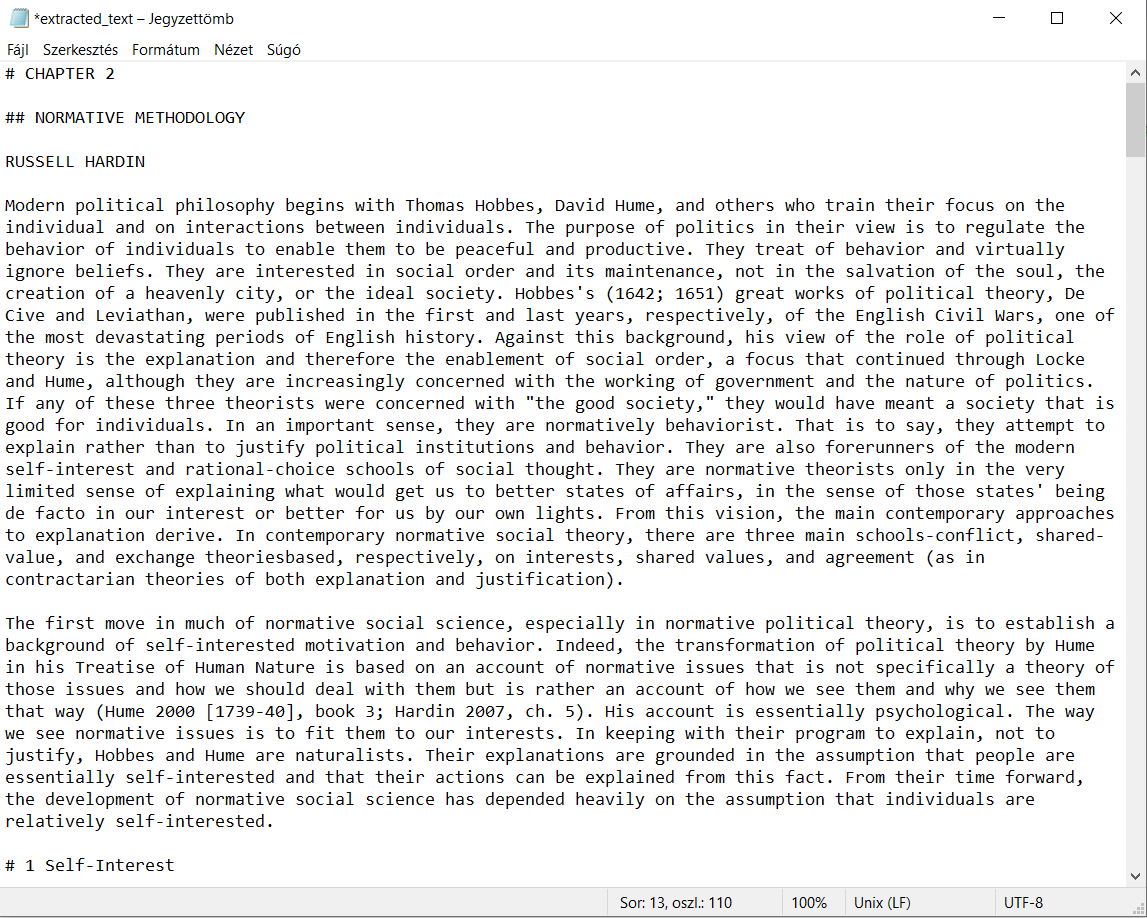
The resulting .txt file was clean, well-structured, and accurately preserved the main body of the text. However, one notable limitation of this GenAI-based approach was its inability to extract footnotes—these were omitted during the process, likely due to their small size or non-standard placement in the scanned file.
Recommendation
For scanned documents where the focus is solely on extracting the main body of the text—without the need to capture footnotes or marginal notes—Mistral Le Chat offers a fast, accessible, and surprisingly accurate solution. The GenAI-based prompt approach delivers clean .txt outputs with minimal setup and no need for additional OCR software. While the omission of footnotes may be a limitation in some contexts, this method is ideal for processing research papers, chapters, and reports where structured content is the primary concern.





