
In our earlier blog post, Harnessing GenAI for Searching Literature: Current Limitations and Practical Considerations, we examined the reliability of generative AI models for scholarly literature searching. To assess whether the newest releases represent any improvement, we tested them on the same narrowly defined academic topic. The results indicate modest gains in certain cases: for instance, OpenAI’s GPT-5 and xAI’s Grok 4 performed more consistently than the models we had previously reviewed. However, key limitations persist. Hallucinated sources and fabricated bibliographic details remain prevalent, particularly in outputs from Mistral and Google’s Gemini family of models — including the most recent Gemini 2.5 Pro. This updated review highlights both incremental improvements and the enduring challenges GenAI tools pose for academic literature search.
Prompt
To ensure comparability with our previous test, we used the same prompt across all models. Each model was asked to return five real scientific articles related to a narrowly defined research topic, complete with accurate bibliographic information.
Give me 5 scientific articles that discuss 'legislative backsliding'. Provide only real references (so don't make up and mix authors, titles and journals on your own), with full bibliography in tabular form.
Output
GPT-5 demonstrated a clear advancement compared to its predecessors. Earlier versions, such as GPT-4o and GPT-4.5, tended to drift from the narrow topic of legislative backsliding into the broader field of democratic backsliding, often producing only two relevant articles before filling the remainder with tangential sources. They also struggled with bibliographic accuracy, including fabricated author attributions, inconsistent dates, and imprecise metadata. GPT-5, by contrast, remained firmly within the specified topic and produced a set of references that were both authentic and complete. It handled online-first publications with methodological rigour, indicating the absence of page numbers rather than fabricating them, and preserved the correct author order throughout. This marks a significant step forward in accuracy and reliability for literature searching.
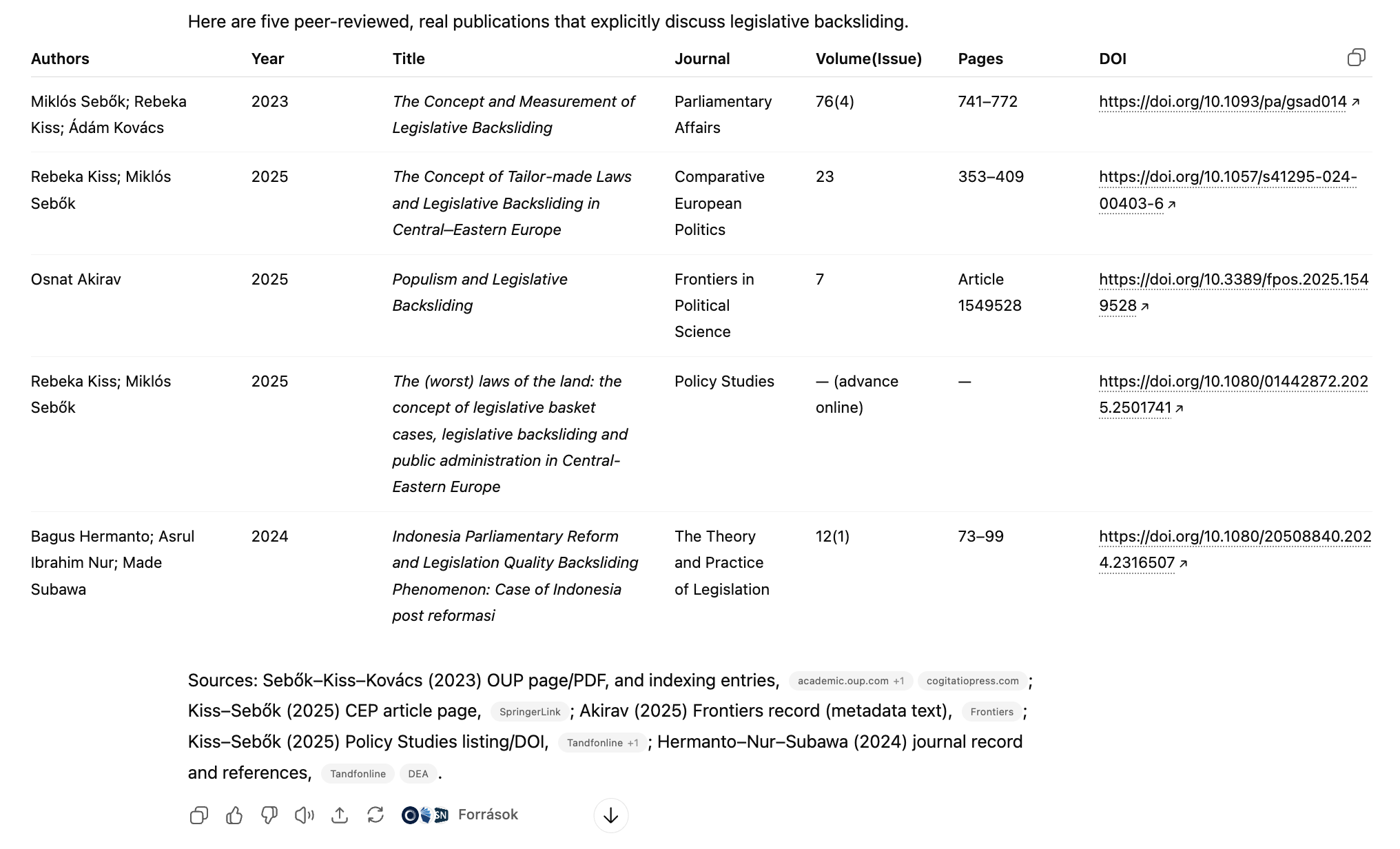
Grok-4 also represents a notable improvement over its predecessor, Grok 3. While Grok 3 successfully identified relevant works, it frequently slipped into the general domain of democratic backsliding and displayed technical shortcomings, such as broken DOIs or links leading to unrelated articles. Grok 4, by contrast, managed to stay closely aligned with the requested topic of legislative backsliding and avoided inventing metadata. All but one of its outputs were directly relevant, and even the less tightly related reference was still within the thematic scope of the search. Its only substantive weakness was the omission of page numbers for one article where this information had already become available, an area where GPT-5 performed better. Nevertheless, compared to earlier iterations, Grok 4 delivered more precise and trustworthy bibliographic data, narrowing the gap with the best-performing models.
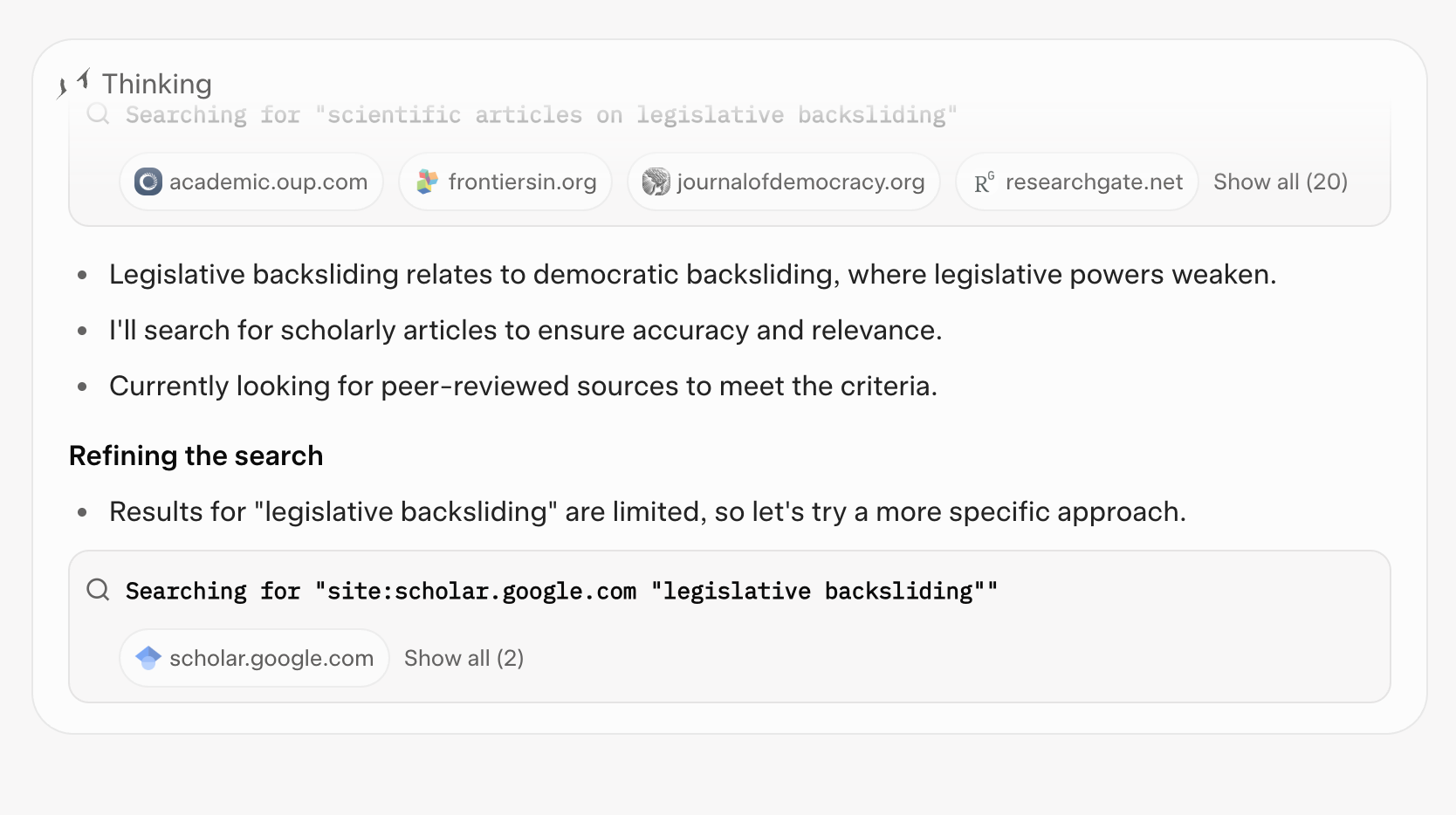
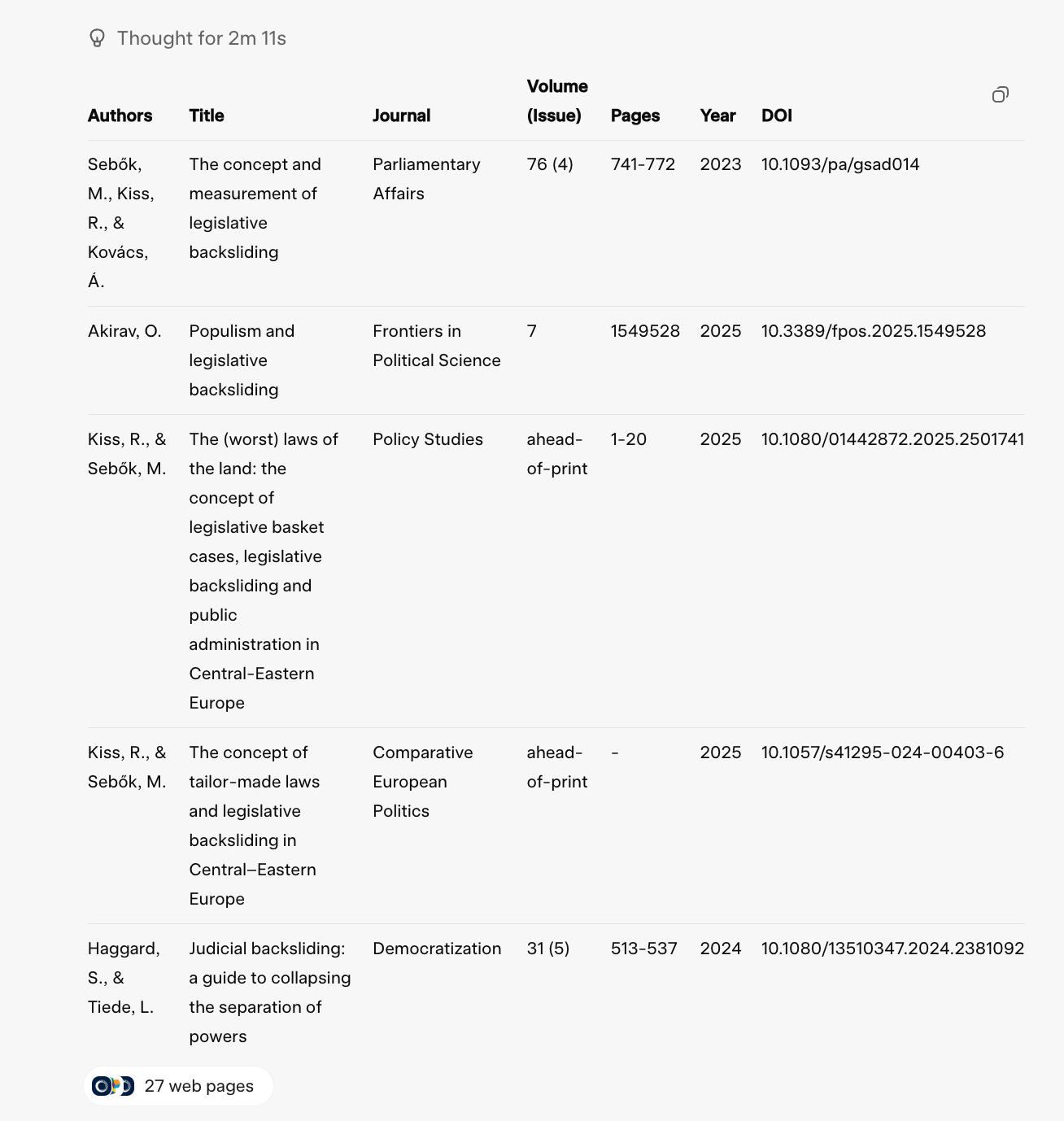
Claude 4 Sonnet did not deliver relevant results for the task. The set of outputs was inconsistent and frequently inaccurate: publication years were mixed up, author attributions were incorrect, and in one case the output did not even meet the criterion of being a peer-reviewed article, instead returning a blog post. Compared to the previous generation, Claude 3.7, this represents a decline in performance. While Claude 3.7 also failed to remain within the narrow scope of legislative backsliding, it nevertheless produced well-known and verifiable academic sources on democratic backsliding. By contrast, Claude 4’s list combined misplaced metadata with unreliable sources, reducing its scholarly utility and demonstrating that the model has not advanced in this area — and in fact performed less consistently than its predecessor.

Mistral once again struggled to provide reliable results for literature searching. Although this time the model did not default to generic placeholders such as “Various” for author names, the overall quality of the output did not improve. Several references contained misattributed or entirely fabricated author lists, while in other cases the DOI links either did not resolve or redirected to unrelated studies. Moreover, the model frequently drifted beyond the narrowly defined topic of legislative backsliding into the broader domain of democratic backsliding, thereby failing to meet the core requirement of the prompt. Compared to its earlier performance, where the main weakness lay in incomplete or vague metadata, the current outputs reveal that the underlying issue of hallucinated content persists. The shift from generic labels to more specific but inaccurate bibliographic entries has not enhanced reliability; instead, it has introduced a new layer of distortion by presenting invented author combinations and unverifiable sources. In short, despite superficial changes in format, Mistral’s results show no substantive progress and remain unsuitable for accurate scholarly literature searching.

Gemini 2.5 Pro produced results that were only loosely connected to the requested topic of legislative backsliding. The list included constitutional theory classics such as constitutional hardball and stealth authoritarianism, but none of these addressed the narrowly defined subject. Bibliographic data were inconsistent, with incorrect years and venues, and one entry resembled a fabricated citation. Compared with Gemini 2.0 Flash, which had already struggled with incomplete and ad hoc outputs, the performance did not improve: the model continues to lack thematic focus and reliable metadata, rendering its results unsuitable for scholarly literature searching.

Recommendations
Our updated review underscores that while certain models — most notably GPT-5 and Grok 4 — now return bibliographic data with greater accuracy than their predecessors, fundamental risks remain. Even the best-performing models cannot eliminate the possibility of hallucinated references or distorted metadata. Researchers should therefore approach GenAI-assisted literature searching with caution, using such outputs only as preliminary guidance and systematically cross-checking every reference against established academic databases such as Google Scholar or library catalogues. Critical scrutiny of bibliographic details remains essential if these tools are to be integrated responsibly into scholarly practice.
The authors used GPT-5 [OpenAI (2025), GPT-5 (accessed on 25 August 2025), Large language model (LLM), available at: https://openai.com] to generate the output.




