
This post demonstrates how LangExtract can be used to structure legal text. Using a single article from an EU regulatory instrument as an example, we show how obligations, deadlines, conditional clauses and sanctions can be extracted into a structured, article-level dataset. Rather than producing a summary, the workflow focuses on identifying the normative elements embedded in the provision and organising them into a transparent and reproducible table suitable for further analysis.
Introducing LangExtract
LangExtract is a Python-based library designed for structured information extraction using large language models. Instead of generating free-form text, it allows users to define a schema and extract specific elements from unstructured documents in a reproducible format. The tool is particularly suited to tasks that require consistent identification of entities, relations, or normative components. Typical applications include legal and regulatory analysis, policy document structuring, contract review, and any research setting where narrative text must be converted into analysable data.
The example provision
We use a single article consisting of five paragraphs. The text contains the typical building blocks that make legal extraction non-trivial: multiple addressees (operators, Member States, competent authorities), conditional clauses (“Where …”), different deadline types (fixed recurring dates, relative deadlines, retention periods), and a sanction clause that applies to selected paragraphs only.
Article 12 – Reporting, Monitoring and Enforcement Obligations
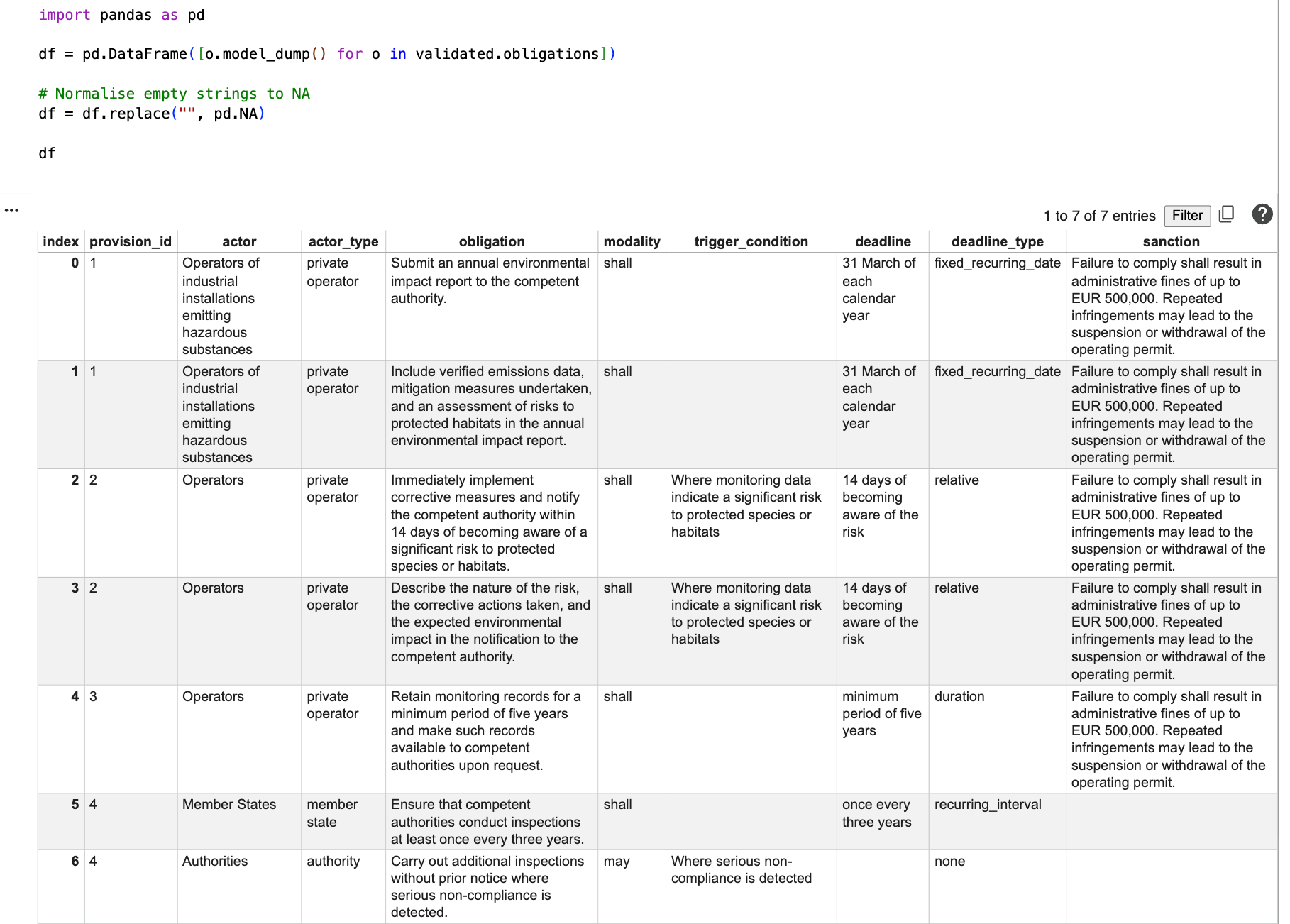
- (1) Operators of industrial installations emitting hazardous substances shall submit an annual environmental impact report to the competent authority no later than 31 March of each calendar year. The report shall include verified emissions data, mitigation measures undertaken, and an assessment of risks to protected habitats.
- (2) Where monitoring data indicate a significant risk to protected species or habitats, the operator shall immediately implement corrective measures and notify the competent authority within 14 days of becoming aware of the risk. The notification shall describe the nature of the risk, the corrective actions taken, and the expected environmental impact.
- (3) Operators shall retain monitoring records for a minimum period of five years and shall make such records available to competent authorities upon request.
- (4) Member States shall ensure that competent authorities conduct inspections at least once every three years. Where serious non-compliance is detected, authorities may carry out additional inspections without prior notice.
- (5) Failure to comply with the obligations set out in paragraphs 1, 2 and 3 shall result in administrative fines of up to EUR 500,000. Repeated infringements may lead to the suspension or withdrawal of the operating permit.
Rather than producing a narrative summary, the aim is to create an article-level table where each row corresponds to one extracted norm. For each row, we capture:
- provision_id (paragraph-level reference, later formatted as Article 12(…))
- actor and actor_type (e.g. private operator, authority, Member State)
- obligation (the required action, phrased conservatively)
- modality (shall / may, etc.)
- trigger_condition (if the obligation is conditional)
- deadline and deadline_type (fixed recurring date, relative, duration, recurring interval, none)
- sanction (propagated to the relevant obligations when the sanction clause has explicit scope)
The minimal workflow
The Python script follows a simple three-step pipeline:
- Define a schema
A structured model specifies which elements must be extracted from the legal text, including the provision identifier, actor, modality, obligation, trigger condition, deadline, deadline type and sanction. This ensures that the output is structured and machine-readable. - Run structured extraction
The legal provision is sent to the language model with instructions to return JSON that strictly conforms to the predefined schema. Each extracted norm becomes a separate entry in the output. - Convert and normalise the results
The structured JSON is converted into a pandas DataFrame. Paragraph identifiers are formatted consistently, mandatory (“shall”) and discretionary (“may”) clauses are separated, and deadline categories are standardised for clarity.
The final output is an article-level table where each row represents one extracted norm.
The complete Python script used in this demonstration is available below:
Output
The extraction performs well in identifying the core normative structure of the provision. Mandatory (“shall”) and discretionary (“may”) clauses are clearly separated, conditional triggers are captured, and different types of deadlines — fixed recurring dates, relative deadlines and recurring intervals — are correctly classified. The sanction clause is also attached only to the paragraphs it explicitly covers, which is crucial for analytical accuracy.
At the same time, the output reflects methodological choices about granularity. Some paragraphs are split into multiple obligations (e.g. reporting and content requirements), while others combine closely related duties in a single row. This is not an error, but a modelling decision that should be made consistently depending on the research design.
Recommendations
LangExtract is useful well beyond legal texts whenever narrative documents need to be converted into structured, analysable data. It is a strong fit for extracting entities, roles, actions, conditions, timelines and outcomes from sources such as policy papers, consultation responses, meeting minutes, institutional reports, grant calls, and corporate disclosures. In empirical workflows, this makes it easier to build comparable datasets across documents, standardise coding categories, and track changes over time.
The main practical advantage is the schema-first approach: by defining the expected fields upfront, the output becomes more consistent and easier to validate than free-form LLM responses. At the same time, structured extraction does not remove the need for domain judgement. Outputs should be reviewed for boundary decisions (what counts as a separate item), correct attribution (who is responsible for what), and scope (which conditions or consequences apply to which entries). Used carefully, LangExtract can speed up the transition from text to dataset while keeping the process transparent and reproducible.





