
Academia.edu has recently introduced an AI-based Reviewer tool, positioned as a solution for generating structured feedback on academic manuscripts. While the concept is promising, our evaluation revealed a number of significant limitations. We encountered recurring technical issues during both file uploads and Google Docs integration, often requiring multiple attempts before the system produced any output. When reviews were eventually generated, they exhibited a high degree of repetition and generality, with similar phrasing returned for papers of distinct topics and disciplines. Based on our observations, the tool—in its current form—provides limited utility for researchers seeking substantive and targeted pre-submission feedback.
The Academia.edu AI Reviewer allows users to request feedback on academic drafts by either uploading a file or providing a Google Docs link. According to the platform, the tool draws on insights from a corpus of 100 million peer-reviewed papers to generate a structured review of around 600 words. This feedback is intended to help researchers refine their work before submitting it to a journal. Notably, users are not required to publish their draft publicly or add it to their Academia.edu profile; instead, they can either provide a Google Docs link or upload a file directly, with the assurance that the document will remain private and will not be shared or modified in any way by the AI Reviewer.
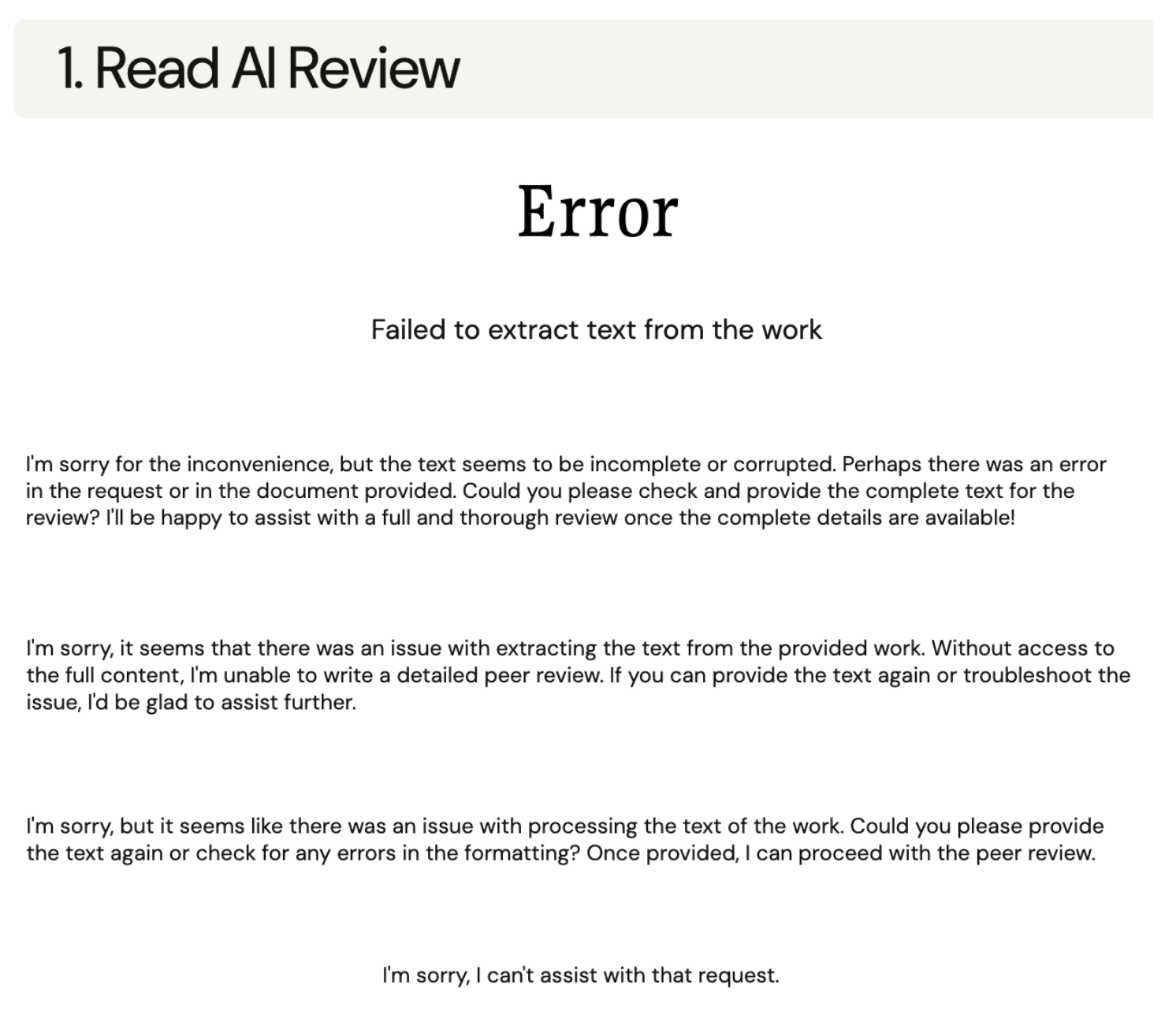
Our initial attempt involved linking a Google Docs version of the manuscript. Despite submitting the exact same document multiple times without any changes, the tool repeatedly failed to extract the text, displaying a range of error messages. A review was eventually generated after four or five attempts, indicating that the system may still experience occasional difficulties in reliably processing shared documents.
We also tested the file upload option, using the same manuscript in PDF format. On several occasions, the process resulted in error messages, and the AI Review did not appear to start. While the platform offers this as a convenient alternative, the file upload feature did not function consistently in our tests.
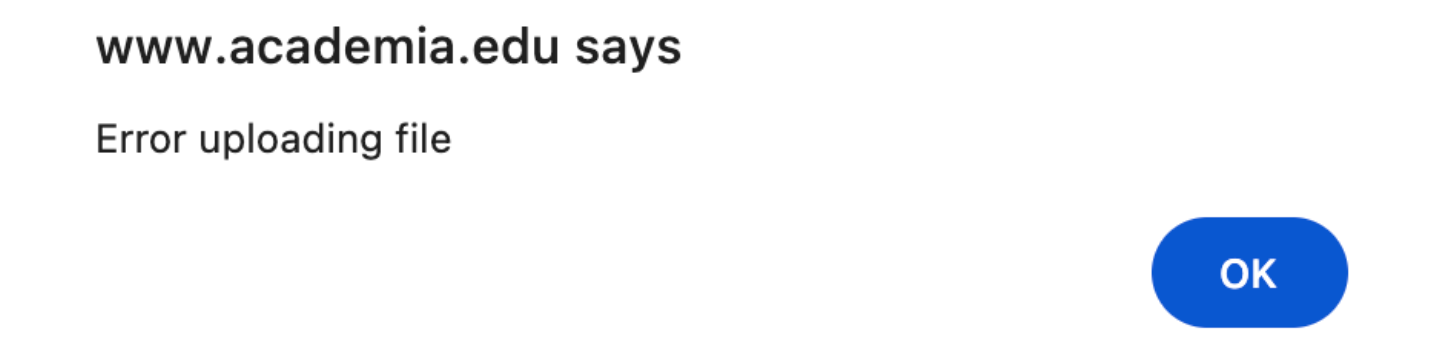
One of the papers we submitted for evaluation was Introducing HUNCOURT: A New Open Legal Database Covering the Decisions of the Hungarian Constitutional Court for Between 1990 and 2021. The AI Reviewer produced several comments that showed limited engagement with the actual content of the article. The suggestion to add a glossary, for example, was unwarranted, as the paper does not introduce unfamiliar technical language that would require clarification. Likewise, the recommendation to include diagrams appeared superficial, given that the structure and function of the database are already described in detail.

More notably, the major comments suggested the inclusion of a discussion on predictive modelling and algorithmic bias—issues that fall outside the scope of the paper. The article does not present or imply any use of algorithmic forecasting, nor does it position HUNCOURT as a tool for automated decision-making. Rather, the database is introduced as a source for empirical legal analysis and open legal scholarship. This mismatch suggests that the AI-generated review relied on generic assumptions about legal informatics, rather than engaging with the specific goals and content of the paper.

The second paper we submitted, Leveraging Open Large Language Models for Multilingual Policy Topic Classification: The Babel Machine Approach, initially triggered an access error despite correct file upload procedures. Once the system processed the submission, the resulting review followed a standardised template and failed to engage with the paper’s core objectives. Suggestions—such as elaborating on widely understood evaluation metrics—appeared misaligned with the paper’s scope and intended audience, further underscoring the generic nature of the feedback.


The third paper submitted, Staying on the Democratic Script? A Deep Learning Analysis of the Speechmaking of U.S. Presidents, also received a formulaic AI review. As with the previous cases, the comments largely repeated generic observations—such as the supposed need for a glossary and more descriptive figure captions—without demonstrating any engagement with the article’s actual contributions. The paper is aimed at a political science audience familiar with both deep learning applications and presidential communication research, making these suggestions largely irrelevant. As with the previous reviews, the comments suggest a reliance on generic reviewing heuristics, rather than a careful reading of the paper’s aims, methods, and findings.


Recommendations
In its current form, the Academia.edu AI Reviewer provides limited value for researchers seeking useful, field-appropriate feedback on their manuscripts. Our tests showed that the tool often returns repetitive and overly general suggestions, with little evidence of meaningful engagement with the actual content, methodology, or disciplinary context of the submissions. While it may offer superficial guidance for early-stage drafting or non-specialist users, it falls short of supporting serious academic preparation or discipline-specific refinement.


