
Log probabilities (logprobs) provide a window into how confident a language model is about its predictions. In this technical implementation, we demonstrate how to access and interpret logprobs via the OpenAI API, using a series of increasingly difficult multiplication tasks. Our experiment reveals that declining confidence scores can effectively signal when to scrutinize model outputs—but high confidence does not always guarantee correctness.
Introduction
When working with large language models, understanding the certainty behind their responses can be as important as the responses themselves. Log probabilities offer a quantitative measure of this confidence, revealing which tokens – i.e. chunks of the output text – the model considered most likely at each step of generation.
In this post, we demonstrate how to extract and interpret logprobs using OpenAI's API (specifically GPT-5.2). We test the model's arithmetic capabilities with progressively larger multiplication problems, examining how confidence scores evolve as task difficulty increases. We also explore a classic case—the "strawberry" letter-counting task—to illustrate an important limitation: high logprobs can correspond to incorrect answers, making them a useful but imperfect diagnostic tool.
Prerequisites and Setup
To replicate this implementation, you will need:
- Python 3.7+
- OpenAI Python library (
openai) - Google Colab (optional, for accessing API keys via
userdata) - Valid OpenAI API key with access to GPT-5.2
If not yet installed, install the required library with:
pip install openaiStore your API key securely. In Google Colab, you can use the userdata feature to avoid hardcoding credentials.
Code Implementation
We attached the full script used for this task below. The most important section can be seen here:

This handles the following tasks: 1) it defines the prompt we send to the model, 2) sets a minimum probability threshold (0.0001) under which the code does not display alternatives, and 3) specifies the details of the API request. In the specification, we set logprobs=True to enable log probability extraction and top_logprobs=5 to retrieve the top 5 alternative tokens at each position.
The rest of the script is dedicated to setting up the API call and processing the responses. In the output, we display logprobs (`logp') and the exponentiated value of logprobs (`p'). The latter can be interpreted as the confidence of the model that a given token should follow conditional on the preceding text.
Output and Analysis
We tested GPT-5.2 on a series of multiplication tasks, starting with simple arithmetic and progressively increasing complexity:
Simple Arithmetic (High Confidence)
How much is 2*2? Respond only with a number.
Correct Answer: 4
Model output:

The model produces the correct answer with near-perfect confidence (p=0.999998). No alternative tokens are considered.
Moderate Complexity (Sustained Confidence)
How much is 97*97? Respond only with a number.
Correct Answer: 9409
Model output:
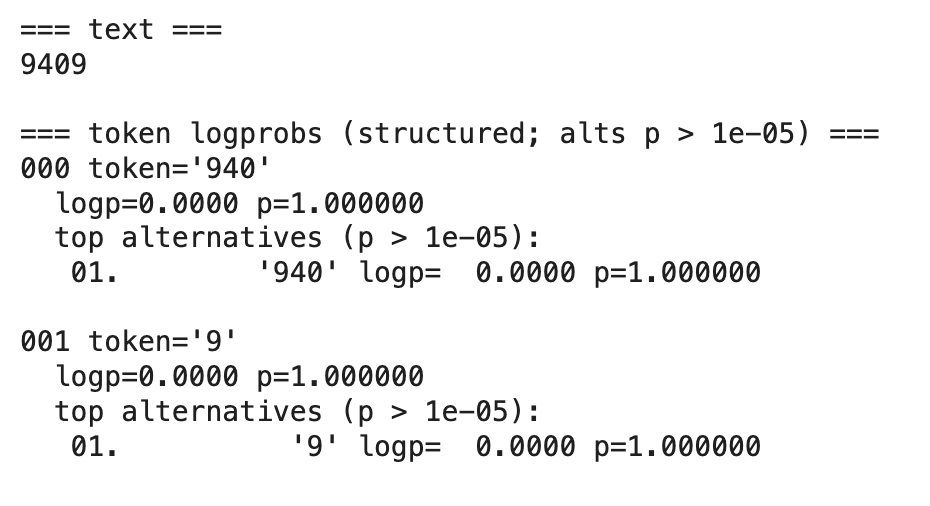
Interestingly, here, the model processed the answer in two steps, leading to two output tokens. The model maintains perfect confidence across both tokens – without considering any alternatives – and produces the correct result.
Emerging Uncertainty (Correct but Less Certain)
How much is 971*971? Respond only with a number.
Correct Answer: 942841
Model output:
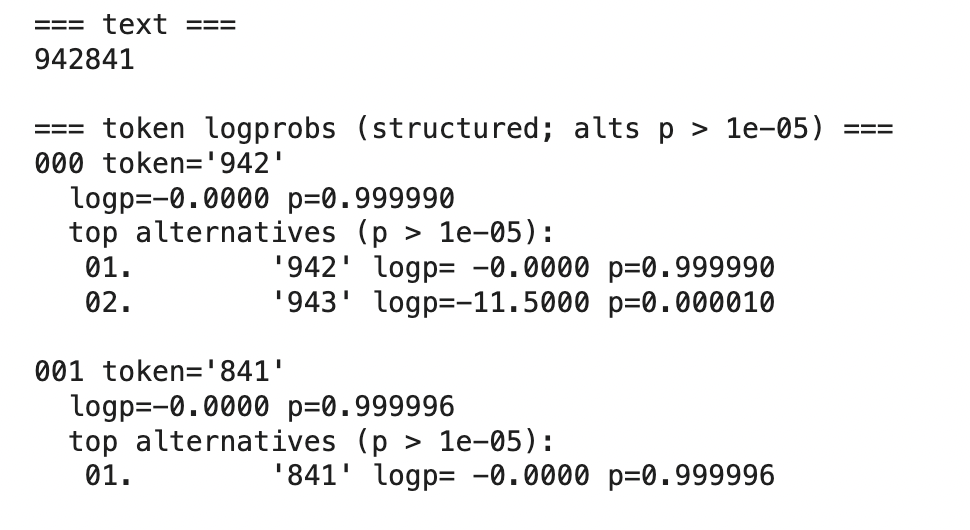
Here we see the first appearance of an alternative token ('943') with non-negligible probability, though the model still produces the correct answer with very high confidence.
Clear Uncertainty Signals Errors
How much is 9713*9713? Respond only with a number.
Correct Answer: 94342369

This is where logprobs first prove their diagnostic value. The model's answer (94342569) is incorrect—the correct answer is 94342369. Notice that the second token ('425') has a probability of only 0.617599, with '424' appearing as a strong – but, again, incorrect – alternative (p=0.227202). This distributional uncertainty correctly signals that the model is struggling with this calculation.
The uncertainty remains as we increase the complexity further:
How much is 97138*97138? Respond only with a number.
Correct Answer: 9435791044
Model output:

The model's answer (9435803044) is again incorrect. The logprobs reveal significant uncertainty at both the second token ('580', p=0.619408) and third token ('304', p=0.938441), with multiple plausible alternatives. This pattern of distributed probability across tokens can be seen as a warning for potential error.
The Strawberry Paradox: High Confidence, Wrong Answer
How many r's are there in 'strawberry'? Respond only with a number.
Correct Answer: 3
Model output:
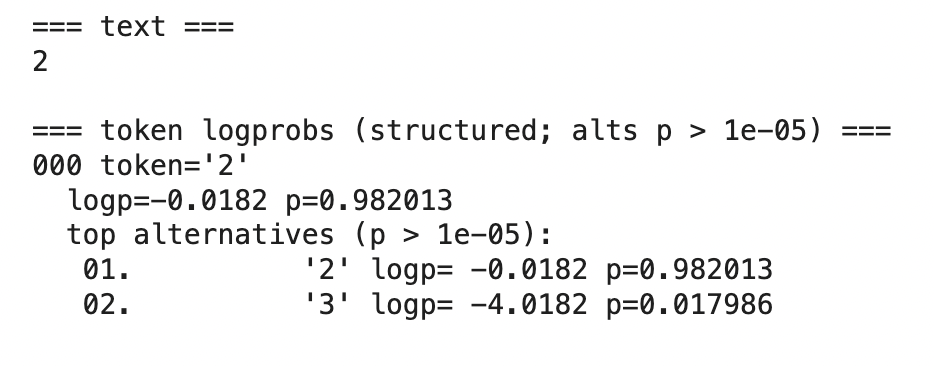
With this last example, we illustrate a critical limitation of logprobs. The model confidently answers "2" with p=0.982013, yet the correct answer is "3" (appearing as an alternative with only p=0.017986). The word "strawberry" contains three instances of the letter 'r', but the model's high confidence masks its error. This demonstrates that logprobs measure the model's certainty about what it predicts—not the correctness of that prediction.
Recommendations
Log probabilities provide a valuable diagnostic tool for understanding model behavior, especially when working with tasks that push the boundaries of a model's capabilities. Our multiplication experiment demonstrates that declining confidence scores can effectively signal when a model is likely to produce errors—making logprobs particularly useful for quality control workflows.
However, the strawberry example underscores an important limitation: logprobs measure the model's certainty about its prediction, not the correctness of that prediction. High confidence can correspond to wrong answers.
For researchers and developers working with API-based LLMs, we recommend treating logprobs as one component of a broader validation strategy. They are most useful when combined with task-specific evaluation, domain expertise, and awareness of a model's known limitations. Note also that information on logprobs is not available in all API configurations. In the case of OpenAI, for example, reasoning models do not support this output.
---
The authors used GPT-5.2 [OpenAI (2025) GPT-5.2, Large language model (LLM), available at: https://openai.com] to generate the outputs analyzed in this post.



