One of the key promises of recent generative AI models is their ability to process not only text and images but also audio and video content. GPT-4.5, with its apparent support for MP3 and MP4 file uploads, seems like an ideal tool for tasks such as transcription — particularly for researchers in the social sciences and humanities, where interview transcriptions, lecture recordings, and focus group discussions form an essential part of qualitative data collection. However, a closer inspection reveals a significant limitation: the model cannot actually transcribe audio files via the chat-based interface.
In this post, we walk through these limitations in detail — illustrating how GPT-4.5 falls short when handling audio transcription tasks, despite supporting file uploads. We present the exact prompt used, the errors encountered, and our attempt to use the Hugging Face-hosted Whisper interface. Finally, we demonstrate a fully functional workaround: running OpenAI’s Whisper model through a simple Python script in an external environment (such as Google Colab), successfully delivering a complete and accurate transcript. This hands-on approach offers researchers a practical and reproducible solution when built-in tools prove insufficient.
Input file
The audio file used in our test was an MP3 version of the following YouTube video:
POLITICAL THEORY – John Rawls (© The School of Life)
The recording offers an engaging, accessible summary of the political philosophy of John Rawls — one of the most influential political theorists of the 20th century. It introduces Rawls’s central concepts, such as the “original position,” the “veil of ignorance,” and his two principles of justice.
Prompt
To test GPT-4.5's transcription capabilities, we uploaded a 15-minute MP3 file containing a lecture on political theory. The task was straightforward: provide a verbatim transcript with accurate punctuation and speaker cues.
Please generate a precise and complete verbatim transcript of the spoken English content in the attached MP3 audio file. The transcription should include all spoken words, rendered accurately with correct grammar, spelling, and punctuation. Non-verbal sounds (e.g. [laughter], [music], [applause]) should be marked in square brackets where clearly identifiable. Do not summarise, paraphrase, or translate – provide the full original speech as it is spoken. The final transcript must be delivered as plain text (.txt), suitable for export and further processing.
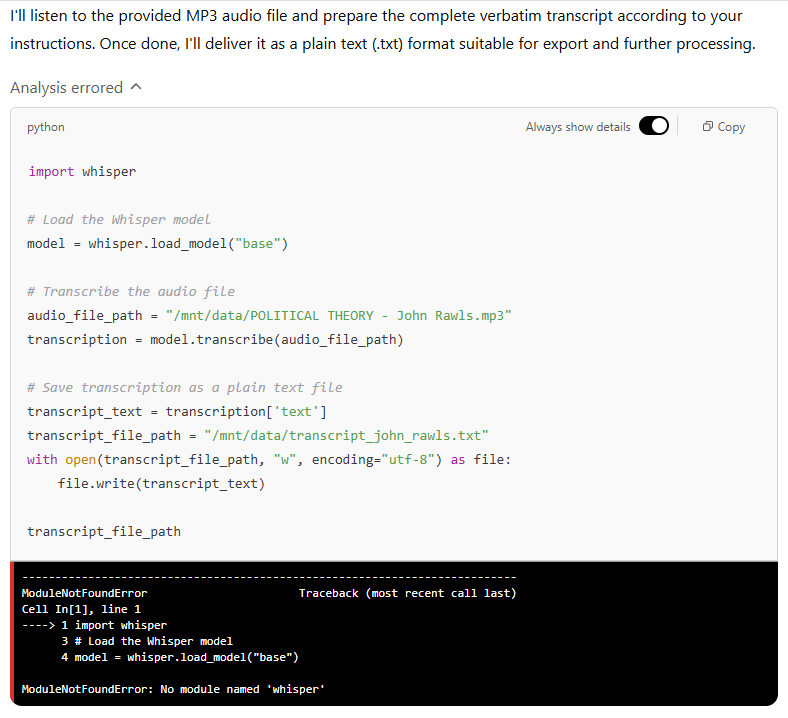
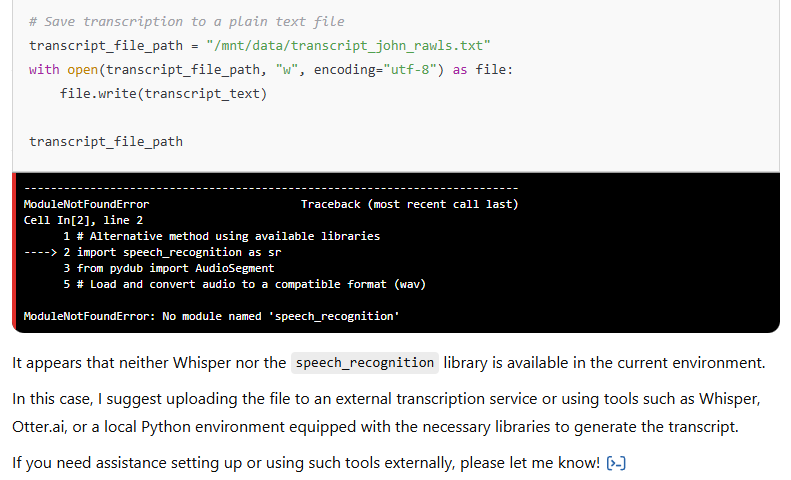
Although GPT-4.5 correctly recognised the nature of the task and acknowledged the uploaded audio file, it quickly ran into execution issues. The model attempted to invoke the whisper library — OpenAI’s own automatic speech recognition tool — but failed due to its absence in the current environment. It then suggested falling back on the more traditional speech_recognition library, combined with pydub for audio conversion. However, this pathway also failed, as neither of these libraries was available or callable within the chat interface.
OpenAI Whisper Large V3 via Hugging Face
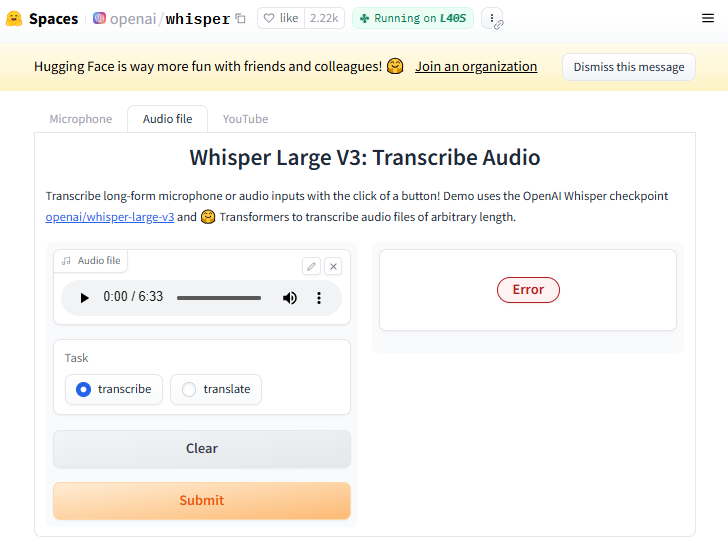
Following GPT-4.5’s failure to execute the transcription internally, we turned to a widely recommended alternative: the Hugging Face implementation of OpenAI’s Whisper model. In theory, this interface allows users to upload audio files and receive transcriptions with a single click, using the whisper-large-v3 checkpoint. However, our experience proved otherwise. Even when uploading a relatively short 6-minute excerpt from the same source material, the system returned a generic “Error” message without further explanation (see image). This suggests that the hosted version may have limitations related to file size, format handling, or resource availability — and is therefore unreliable for research scenarios requiring consistent processing of longer or more complex audio inputs. While this route holds promise for lightweight use cases, it ultimately failed to deliver a usable output in our workflow.
Beyond GPT-4.5: A Functional Workflow for Transcribing Audio with Whisper
After exploring several options for transcribing audio — including GPT-4.5 and the Hugging Face demo — we found a solution that delivered consistent and high-quality results. Using OpenAI’s Whisper model within a Python environment, we were able to process the MP3 file and generate a precise, well-formatted transcript. Below, we outline the necessary setup steps and share the full script used in our workflow.
Before running the transcription script, a few essential packages must be installed to ensure everything works smoothly. These components allow the Whisper model to run properly, handle audio files, and perform transcription tasks efficiently:
openai-whisper: This is the actual transcription model developed by OpenAI.torch,torchvision,torchaudio: These libraries provide the backend for running deep learning models (like Whisper), including support for audio processing.ffmpeg: A powerful multimedia framework required by Whisper to read and convert audio files (e.g. from MP3 to raw waveform format).
Once installed (in environments like Google Colab, installation usually takes under 2 minutes), the system is ready to transcribe audio files with just a few lines of code.
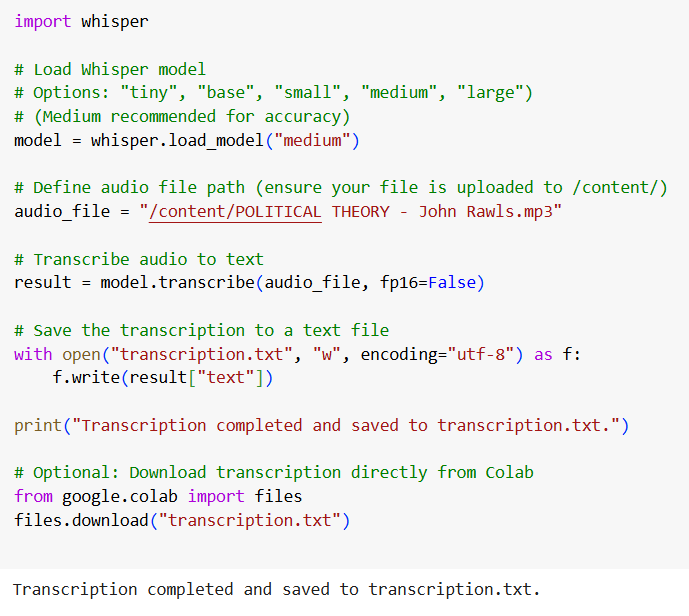
The full script shown above is available for download below.
Output
The output matched our expectations exactly: a full, accurate, and properly formatted verbatim transcript. Every spoken word was captured faithfully, with correct spelling and punctuation. No parts were summarised or omitted — just the raw text, ready for further use in research or documentation.
Recommendations
At present, generative AI models accessed through chat-based interfaces — such as GPT-4.5 — are not capable of transcribing audio files directly, even if they allow file uploads. While there are alternative GenAI-powered tools designed for transcription, many of these come with limitations: they are often paid services, have file duration caps, or fail to process longer recordings reliably. The Whisper-based script shared above remains the best option if you're looking for a free, accurate, and researcher-friendly solution. It offers full verbatim transcriptions with minimal setup, making it ideal for interviews, lectures, and other spoken research materials.
The authors used GPT-4.5 [OpenAI (2025) GPT-4.5 (accessed on 24 April 2025), Large language model (LLM), available at: https://openai.com] to generate the output.