
Can a language model accurately classify argumentative claims without any prior examples or fine-tuning? We put DeepSeek-V3 to the test on a real-world stance classification task involving 200 claims from a structured dataset. The model was asked to determine, for each claim, whether it supported (PRO) or opposed (CON) a given topic – and the result was surprising: DeepSeek-V3 labelled all 200 claims correctly, achieving a perfect 100% accuracy without any additional training or manual adjustments.
Input file
The input was a 200-row sample extracted from the IBM Debater® Claim Stance Dataset, a resource designed for evaluating argument mining systems. Each row contained a short topic statement (e.g. “This house supports the one-child policy of the Republic of China”) and a claim related to that topic (e.g. “The reduction in the fertility rate and thus population growth has reduced the severity of problems that come with overpopulation”). The task for the model was to decide whether each claim aligned with or opposed its associated topic — corresponding to a PRO or CON label, respectively — using only this minimal structure, with no extra metadata or external context.
Prompt
You are given an Excel spreadsheet with three columns:
- Column A: ID – an identifier for each row.
- Column B: TOPIC – a short policy statement or proposition.
- Column C: CLAIM – a sentence that expresses a view related to the topic.
Your task is to determine, for each row, whether the CLAIM supports or opposes the TOPIC.
Write your answer in a new column labeled “STANCE” (Column D), using one of the following two labels only:
- PRO – if the claim clearly supports or argues in favour of the topic.
- CON – if the claim clearly opposes or argues against the topic.
You must assign exactly one label – either PRO or CON – to each row.
Even if the relationship is ambiguous, unclear, or context-dependent, you are required to choose the label that best fits the claim based on its wording and apparent intent.
Do not return explanations or alternative interpretations.
Only return the completed Excel file, with the new STANCE column filled in, preserving the original structure and row order.
Output
The resulting output was remarkably consistent. DeepSeek-V3 correctly assigned a PRO or CON label to each of the 200 claims, fully matching the expected stance derived from the IBM dataset. As illustrated in the output preview, supportive claims (e.g. “The policy had proved remarkably effective”) were accurately labelled as PRO, while critical or sceptical statements (e.g. “The one-child limit is too extreme. It violates nature’s law”) were correctly categorised as CON.
The model handled a range of argumentative styles — from factual assessments to normative judgements — with no apparent confusion, even in nuanced or indirectly phrased cases. The results were manually validated against the original stance annotations provided in the IBM Debater® dataset, confirming that all 200 predictions matched the expected labels.

The only drawback was a practical one: DeepSeek-V3, in its current interface, does not support downloadable file outputs. This meant the results had to be manually copied from the interface and pasted back into an Excel file — a minor inconvenience considering the otherwise perfect performance. However, this limitation also affects scalability: the model's output is constrained by the size of its response window. When tested on a larger sample of 300 claims, for example, it was unable to return the full set of labels in a single response. This makes the current setup best suited for small- to medium-scale annotation tasks, unless integrated into a more programmatic workflow.
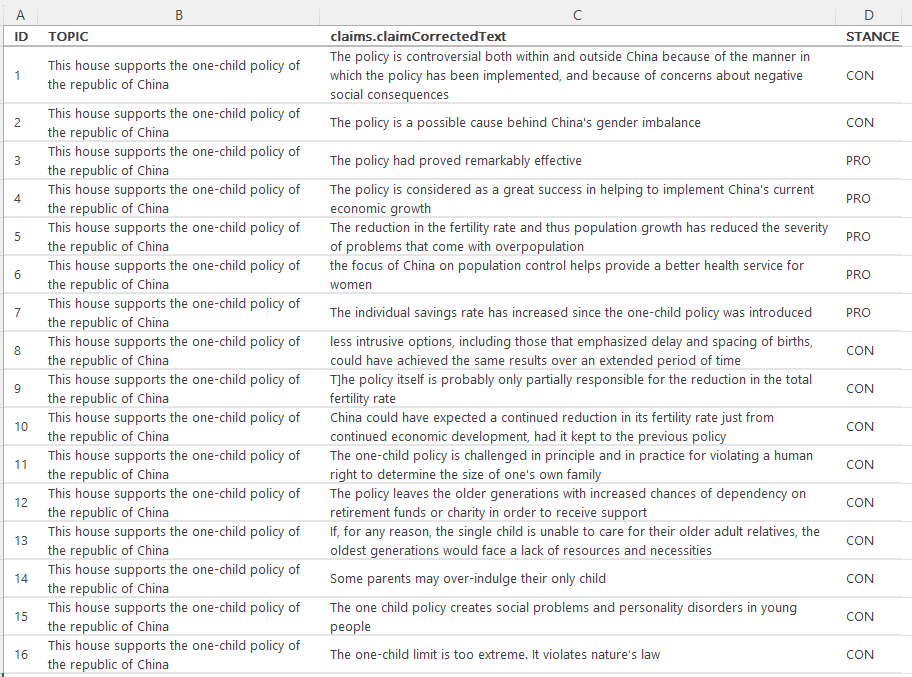
The full labelled output for the 200 claims is available below.
Recommendations
Our experiment shows that DeepSeek-V3 is highly capable of handling binary stance classification tasks with minimal input and no prior examples. It performed consistently and accurately across a variety of argumentative styles, correctly labelling all 200 claims as either PRO or CON based solely on a prompt and a structured Excel input. This level of performance makes DeepSeek-V3 a strong candidate for small- to medium-scale annotation tasks where fast, high-quality results are needed. However, its current limitations — most notably the lack of file export functionality and the constrained output length — mean that scaling beyond a few hundred items requires manual workarounds or programmatic integration.
Still, the results demonstrate the practical value of prompt-based classification using large language models. With careful prompt design, models like DeepSeek-V3 can deliver expert-level labelling without fine-tuning, opening up efficient pathways for research and applied NLP projects.
The authors used DeepSeek-V3 [DeepSeek (2025) DeepSeek-V3 (accessed on 7 May 2025), Large language model (LLM), available at: https://www.deepseek.com] to generate the output.




