
In our previous experiment, we showed how DeepSeek-V3 could classify argumentative claims in a simple prompt-based setup. In this follow-up, we take the test one step further: running the same PRO/CON stance classification task programmatically via the DeepSeek API in a Google Colab environment. This shift from manual prompting to automated workflow highlights how large language models can be integrated into reproducible research pipelines, moving beyond one-off demonstrations towards scalable applications.
Input file
For consistency with our earlier esperiment, we used the same dataset, the IBM Debater® Claim Stance Dataset, which is designed for evaluating argument mining systems. In this API-based test, the model received a 100-row sample extracted from the dataset. Each row contained a short policy topic statement (e.g. “This house supports the one-child policy of the Republic of China”), and a claim related to that topic (e.g. “The reduction in the fertility rate and thus population growth has reduced the severity of problems that come with overpopulation”).
To run the experiment in Google Colab, you will first need to create an API key on the DeepSeek Platform. Once generated, the key can be stored securely in the Colab userdata environment. This way, the key never appears directly in the notebook code.

Script
The Colab script follows a straightforward workflow. After installing the necessary Python libraries (pandas, openpyxl, requests), it loads the Excel file containing the topics and claims. The DeepSeek API key is then retrieved securely from the Colab userdata environment.
A helper function is defined to handle the classification. For each row, this function takes the topic and the claim, places them into a simple prompt, and sends the request to the DeepSeek endpoint. The prompt instructed the model to return only one label — PRO if the claim supports the topic, or CON if it opposes it — with no explanations or additional text.
The response is parsed so that only the one-word answer (PRO or CON) is recorded. This value is then written back into a new column in the dataframe, ensuring that every row in the dataset is consistently labelled. Finally, the updated dataframe is exported back into an Excel file, so that the results can be easily inspected, shared, or reused in further analysis.
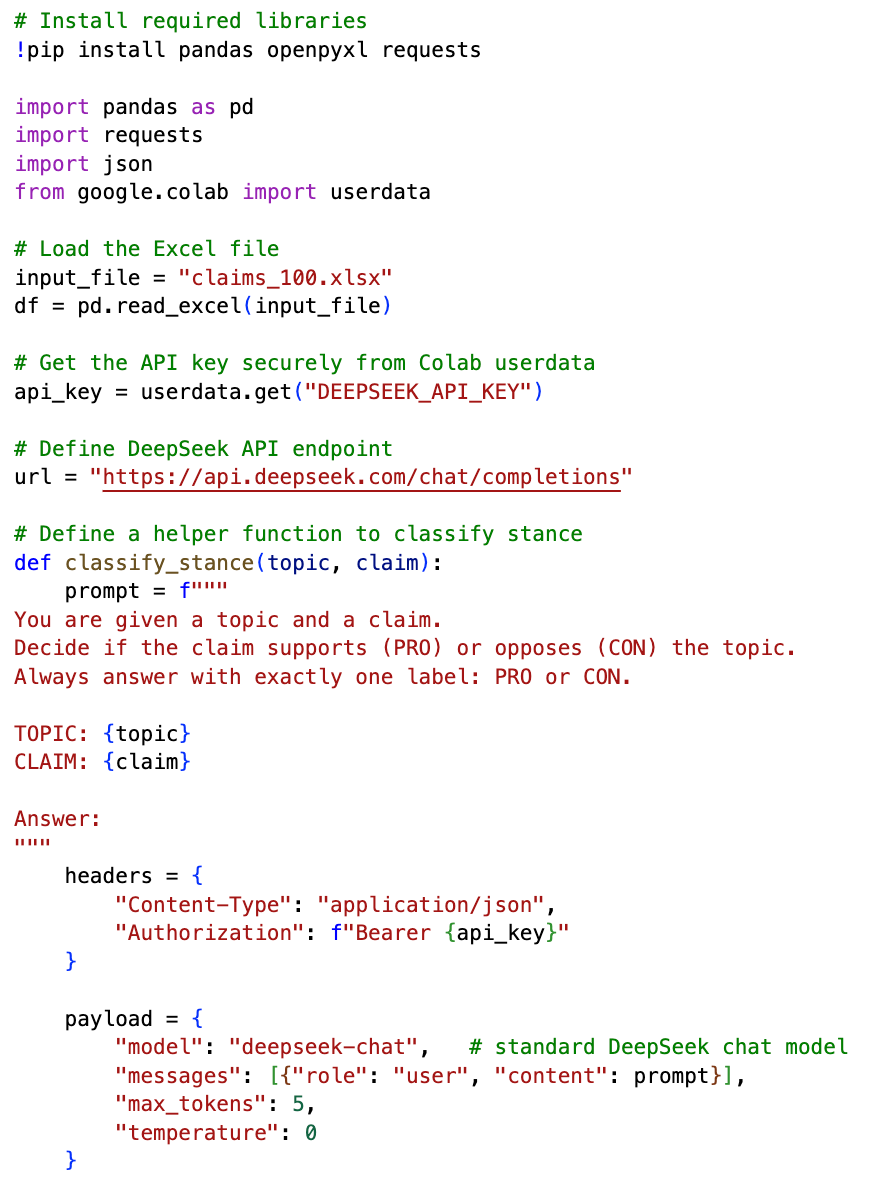
Above you can see a short snippet of the script, while the full code is available for download here:
Output
The results obtained through the DeepSeek API were strikingly strong. While we cannot know whether the IBM Debater® Claim Stance Dataset was part of the model’s training material, the performance suggests a remarkable ability to generalise. Across the 100 claims, DeepSeek-V3 classified the stance with 93% accuracy, mislabelling only a handful of cases. The majority of supportive statements were correctly labelled as PRO and critical or opposing arguments as CON, even when phrased in indirect or nuanced ways. In the output Excel sheet, we highlighted in yellow the rows where the model misclassified the stance. These cases indicate where the predicted label did not match the reference annotation.
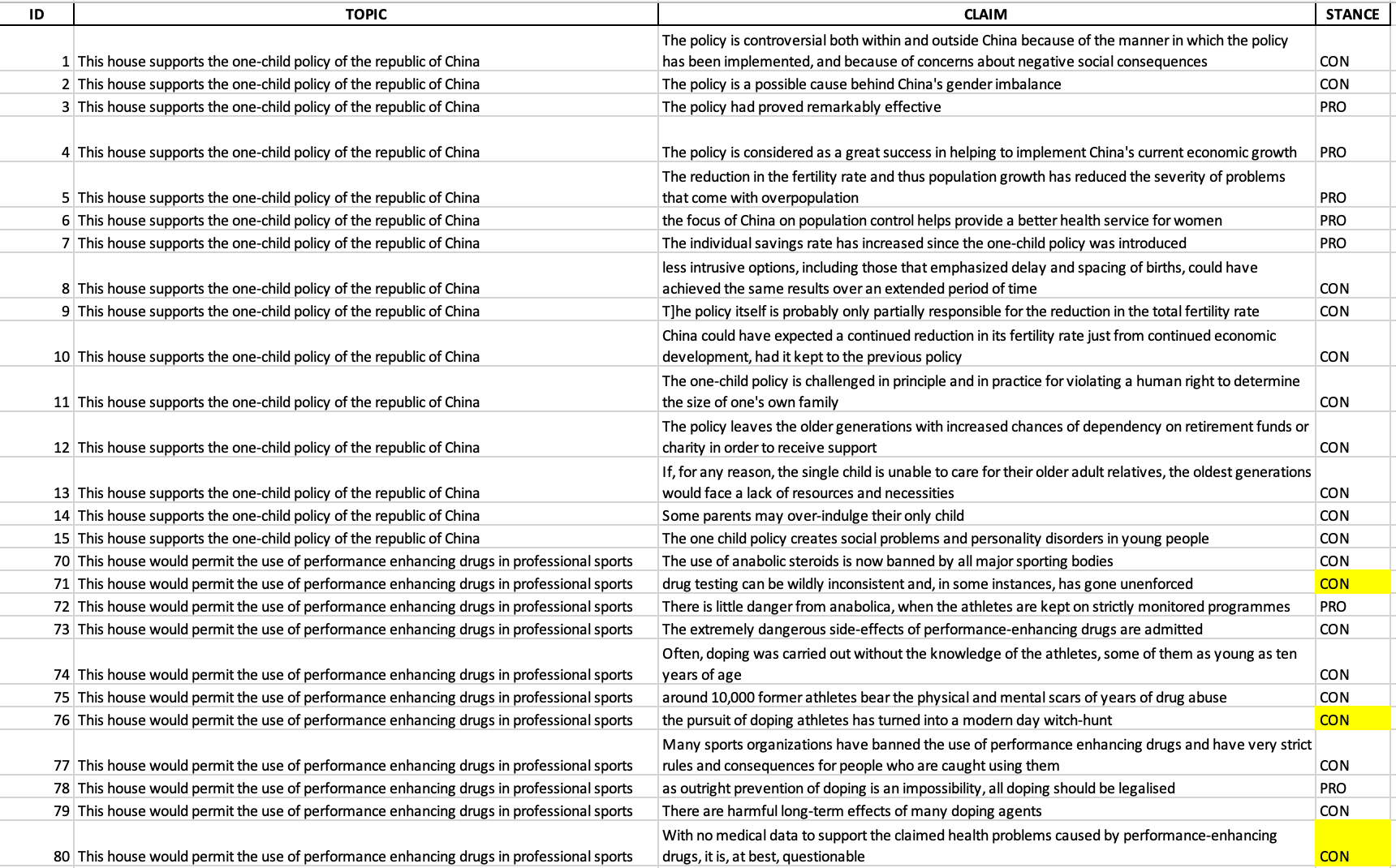
Recommendations
In our previous experiment, we demonstrated how a simple prompt was enough for DeepSeek-V3 to classify argumentative claims accurately. The API-based workflow presented here shows how that same capacity can be scaled up and embedded into a reproducible research pipeline. While a few errors remain, the overall performance highlights the potential of large language models to support small- to medium-scale annotation tasks efficiently.





