
Working with real-world text data often means dealing with structures that are not yet analysis-ready. In our case, the dataset included headlines and full article texts stored separately, across two different tables. The only link between them was a shared identifier field: Body ID. Before we could begin any further analysis or model development, we needed to merge these two sources — connecting each headline with its corresponding article body. This post outlines how we approached that preprocessing task using GPT-4o, and why such a structured merge is worth doing carefully.
Input files
The dataset we worked with originates from the Fake News Challenge (FNC-1), which was designed to support stance detection tasks — that is, determining the relationship between a short headline and the content of a full news article. Rather than providing ready-made pairs, the organisers released the data in two separate files. One file contains headlines and their stance labels. The other stores the corresponding article texts. These two tables are linked only by a shared field called Body ID, which must be used to match each headline with the appropriate article.
train_stances.csvcontains 49,972 rows. Each row includes a shortHeadline, aBody IDindicating which article it refers to, and aStancelabel (such as agree, disagree, discuss, or unrelated).train_bodies.csvincludes 1,684 article texts, each uniquely identified by aBody ID. These articles are often long-form texts with line breaks and multiple paragraphs.
Prompt
Our goal was to create a single, structured table linking each headline to its full article body and stance label. The challenge was that these elements were stored in separate files, connected only by a shared Body ID. Since many headlines referred to the same article, the merge required precise matching. To ensure clarity and traceability, we also introduced a custom ID column in the format <Body ID>_<N>, where N indicates the order of the headline within each article group.
Task:
You are given two CSV files: train_stances.csv and train_bodies.csv. These must be merged into a single Excel table by linking them via the Body ID column.
Input Files:
train_stances.csv: 49,972 rows with the columns:
– Headline
– Body ID
– Stancetrain_bodies.csv: 1,684 rows with the columns:
– Body ID (each is unique)
– articleBody
Objective:
For each row in train_stances.csv, use the Body ID to find the matching article from train_bodies.csv. Merge the matching data into a new row, and assign a unique custom ID for each merged record.
ID Formatting Logic:
Instead of using a single numeric ID, generate a compound identifier in the following format:
<Body ID>_<N>
where:
<Body ID>is the ID shared by multiple headlines<N>is a sequential number starting from 1, representing the order of appearance of the headline within that Body ID group
Example:
If three headlines share Body ID = 712, then their IDs must be:
- 712_1
- 712_2
- 712_3
This applies to every group of headlines sharing the same Body ID.
Step-by-step Instructions:
- For each row in
train_stances.csv, extract the Body ID. - Find the matching
articleBodyintrain_bodies.csvwhere Body ID is the same. - Keep track of how many rows you have already matched with each Body ID — this is the suffix number.
- Construct a new row with the following columns:
- ID (format:
<Body ID>_<N>) - Body ID
- Headline
- articleBody
- Stance
- ID (format:
- After all rows are processed, sort the final table by Body ID (numerically), then by N.
Output Requirements:
- File format: Excel, named
merged_output.xlsx - Number of rows: exactly 49,972
- ID values must follow the
<Body ID>_<N>format and be unique articleBodymust be preserved with all line breaks inside a single Excel cell- Column order: ID, Body ID, Headline, articleBody, Stance
Output
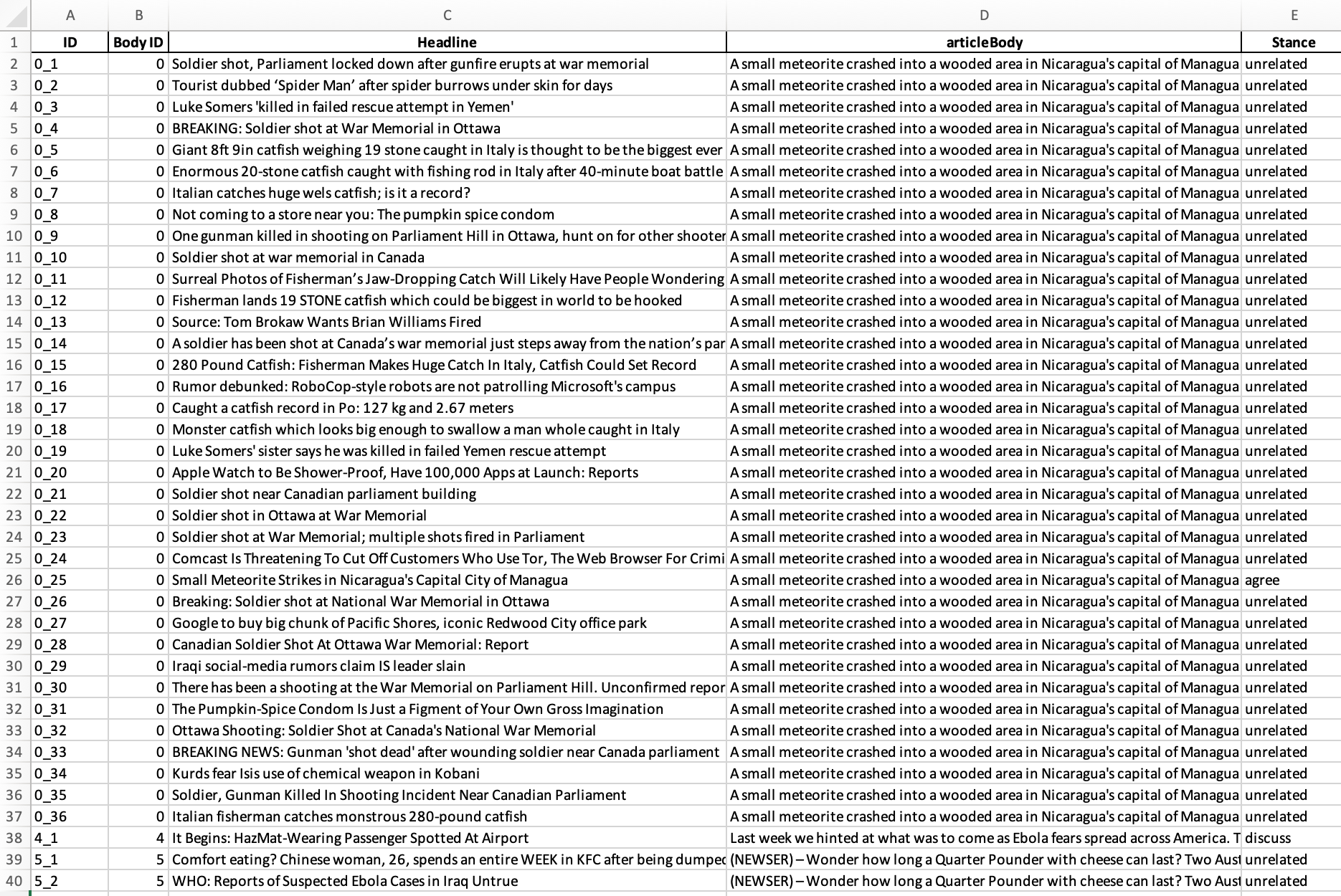
We used GPT-4o to perform this structured merge based on a detailed prompt, ensuring consistent formatting and correct alignment across nearly 50,000 rows. The resulting table fully met our expectations. Each row correctly links a headline to its corresponding article body and stance label, based on an exact Body ID match. More importantly, the custom ID column — introduced to uniquely identify each headline–body pair — was generated as intended. It follows the required format (BodyID_1, BodyID_2, etc.), preserving both uniqueness and logical grouping.
The article body content is preserved in full, including paragraph breaks, and remains intact within a single cell — a critical requirement for downstream processing. The merged table is now well-structured, analysis-ready, and suitable for tasks such as stance classification, claim verification, or content coherence research.
Recommendations
Researchers working with multi-table text datasets should be prepared to invest time in careful preprocessing, especially when elements like headlines and article bodies are stored separately. Merging based on a shared identifier may sound straightforward, but ensuring consistency, traceability, and clean formatting is essential for downstream use — particularly in supervised NLP tasks.Using a structured prompt with a capable model like GPT-4o proved effective for this kind of join operation. While scripting such a merge in code is certainly possible, prompting can be a valuable alternative in cases where logic must be expressed clearly, but flexibility and natural language understanding are also beneficial.
The authors used GPT-4o [OpenAI (2025), GPT-4o (accessed on 28 May 2025), Large language model (LLM), available at: https://openai.com] to generate the output.




