
Can AI detection tools reliably distinguish between human and machine-generated text? In our previous testing, we found that platforms like Originality.ai and ZeroGPT and GenAI models, frequently misclassified both AI and human text. Now, PangramLabs has gained attention with claims of near-perfect accuracy, verified by third-party organizations. In this experiment, we put these claims to the test and found that while the AI detection tool's performance is impressive, it is not infallible: one erroneous classification cropped up even in our small sample experiment.
Testing Approach
To evaluate PangramLabs' real-world performance, we began with materials from a recent experiment where three leading AI models (GPT 5.2, Claude Sonnet 4.5, and Gemini 3) generated cover letters for a real job advertisement based on a fake but plausible CV. The prompt was:
Please write a cover letter for the following job advertisement on behalf of the applicant whose CV you can find attached. The advertisement can be found here: linkedin.com/jobs/view/it-projektmenedzser-at-poltextlab-4289904538
This gave us three AI-generated motivation letters that were stylistically competent and professionally formatted—typical of what AI models produce when asked to generate application materials.
We also included a manually adapted real motivation letter to serve as our human baseline.
To test whether PangramLabs could be fooled by simple rewrites, we also tested the version of these cover letters where we asked each model to rewrite its letter with the following prompt:
Please rewrite the following cover letter so that it does not seem AI-generated. Make sure that this does not decrease the quality of the letter.
The materials used in this experiment can be found here:
All versions—original AI-generated letters, rewritten AI-generated letters, and the human-written baseline—were uploaded to PangramLabs for detection.
Initial Results: Perfect Detection, But a Critical False Positive
PangramLabs identified all of the AI-generated texts—both original and rewritten versions—as "Fully AI Generated" with 100% AI confidence scores. This included the letters where models had explicitly attempted to disguise their AI origins.
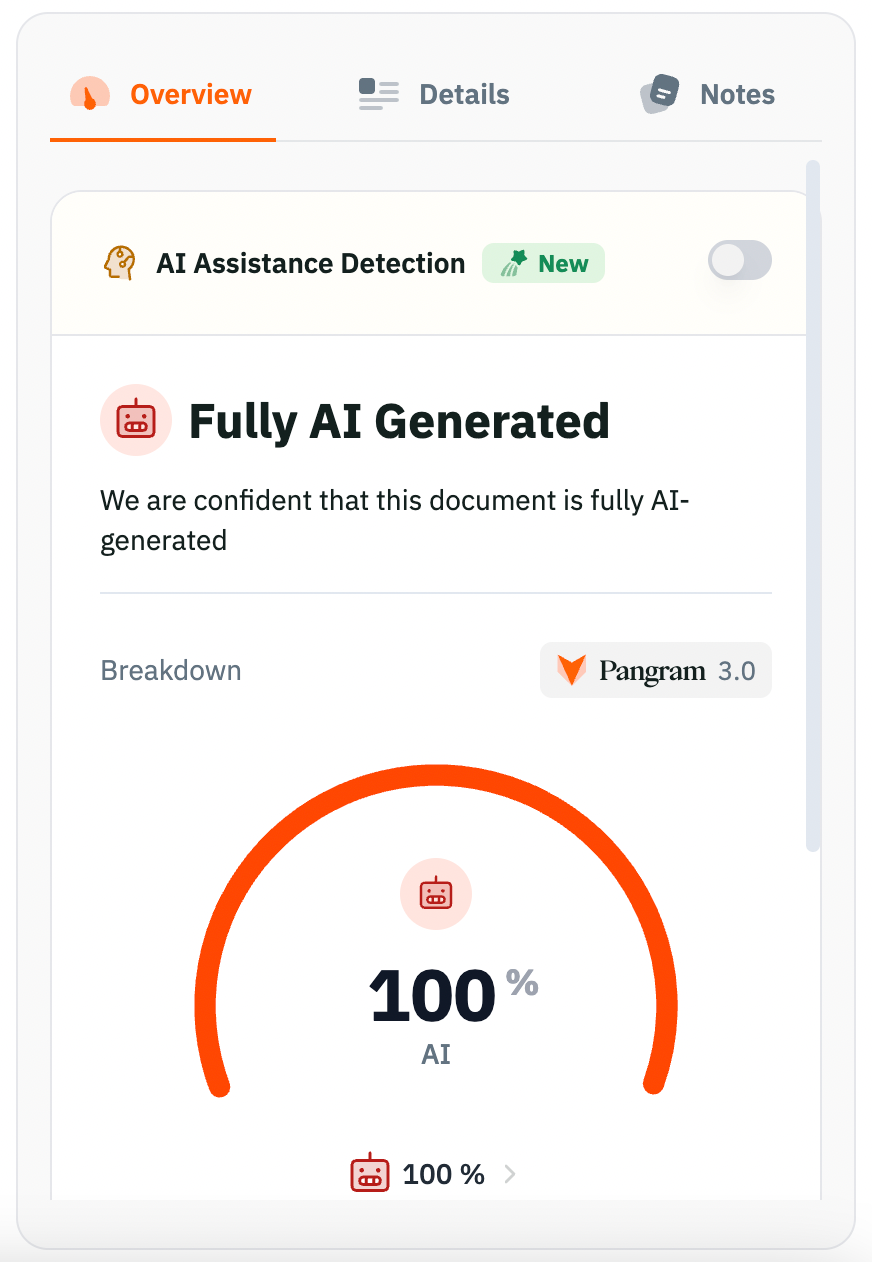
However, there was one considerable problem: the human-written motivation letter was also classified as "Fully AI Generated" with 100% confidence.
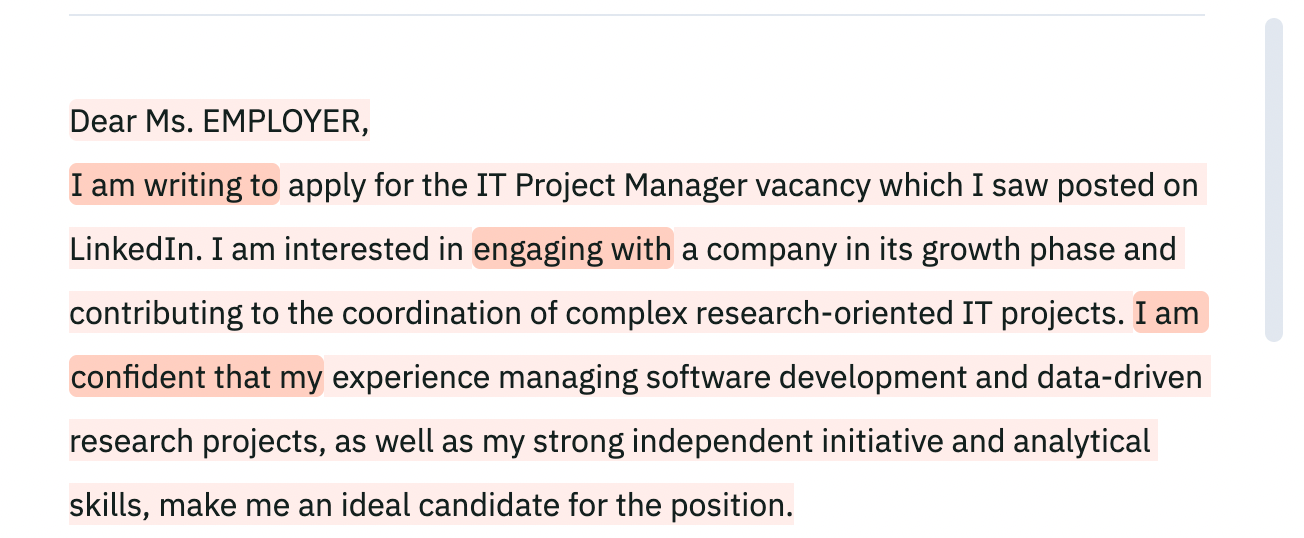
This false positive was concerning. While the tool achieved zero false negatives (correctly identifying all AI text), it failed to accurately recognize genuine human writing. Its output, further, highlighted common formulaic expressions as text which is likely to appear in AI-generated texts (marked with deep red in the following screenshot) – an error that is reminiscent of the logic guiding the misclassifications of GenAI models.
Expanded Testing: High-Quality Human Text
To determine whether the false positive was an isolated case or a broader issue, we expanded our test with three additional examples of high-quality human-written text:
1. A professional motivation letter from a Council of Europe INGO candidate
We selected a publicly available motivation letter written for a position in the Conference of INGOs. The text was clearly human-authored, with personal anecdotes and a distinctive voice.
2. Text from California AI legislation (SB 53)
We used a passage from California's proposed Transparency in Frontier Artificial Intelligence Act, which exhibits the formal, technical style characteristic of legislative documents:
"This bill would enact the Transparency in Frontier Artificial Intelligence Act (TFAIA) that would, among other things related to ensuring the safety of a foundation model, as defined, developed by a frontier developer, require a large frontier developer to write, implement, and clearly and conspicuously publish on its internet website a frontier AI framework..."
3. An article from The New Yorker on AI economics
We tested a section from a recent New Yorker article discussing AI's economic impact, written in the magazine's characteristic analytical style:
"Like many of Marx's works, the passage has been interpreted in various ways. But, taken on its face, it seems to suggest that communism isn't possible until the economy has reached a very high level of output and productivity, which will create new possibilities for organizing society."
Results from Further Human Text Examples
PangramLabs correctly classified all three examples as "Fully Human Written" with 100% human confidence scores.
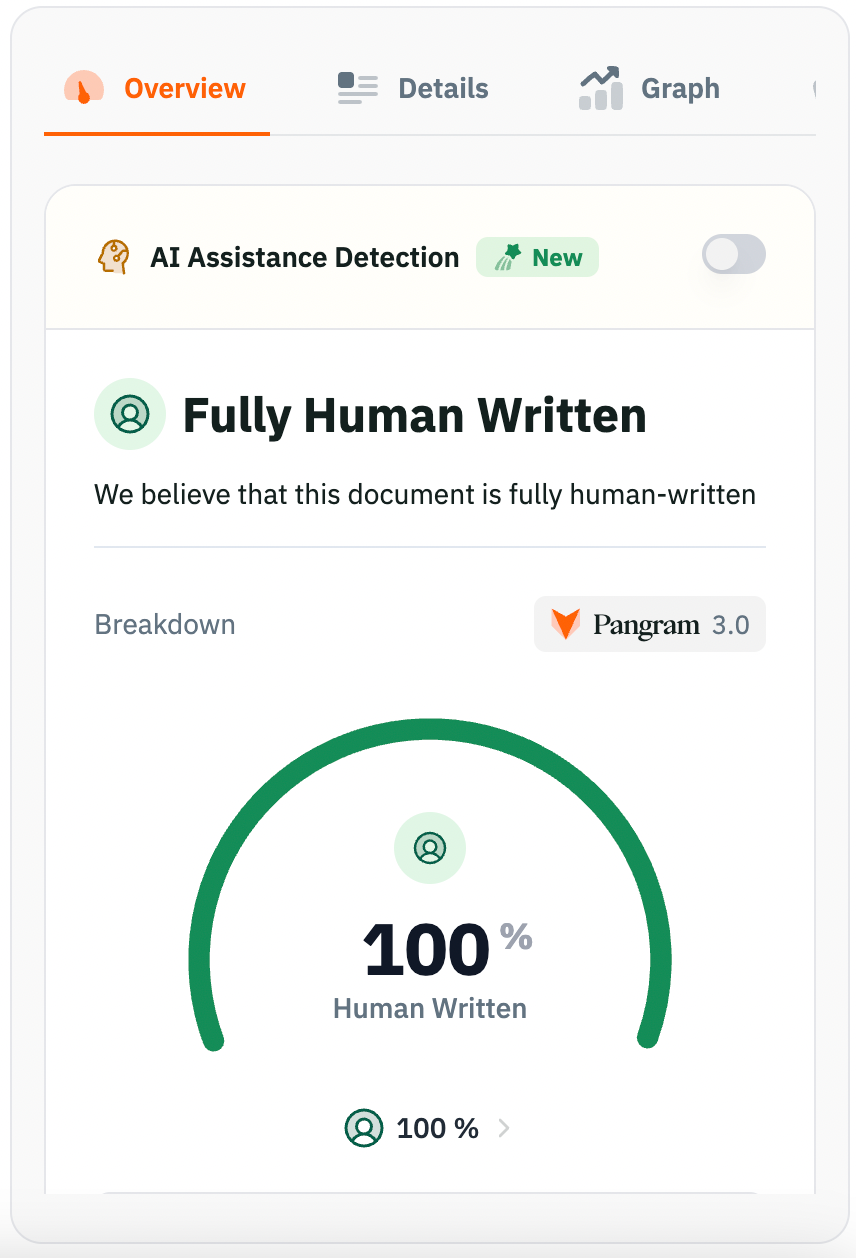
These results provide some more confidence in the reliability of the tool's outputs.
Recommendations
PangramLabs demonstrated an impressive 9/10 accuracy in our experiment. Importantly, it exhibited improved resistance to simple evasion techniques compared to some other detection tools we have tested. However, the presence of a false positive, even in a limited test, raises serious concerns about real-world deployment. In contexts where the stakes are high—such as evaluating job applications, academic submissions, or professional content—even a small false positive rate can have damaging consequences. Therefore, users are advised to be cautious in interpreting the tool's outputs.
The authors used GPT-5.2 [OpenAI (2025), GPT-5.2, Large language model (LLM), available at: https://openai.com], Claude Sonnet 4.5 [Anthropic (2025), Claude Sonnet 4.5, Large language model (LLM), available at: https://www.anthropic.com], and Gemini 3 [Google DeepMind (2025), Gemini 3, Large language model (LLM), available at: https://deepmind.google/technologies/gemini/] to generate the motivation letters used in the analysis.





